
Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables
UIST ‘23
Abstract
aim:让人们能够实时关注于或者忽略特定的声音,同时保留了空间线索(也就是知道声音发出的方位等)
contributions:
1.提出了第一种能够在干扰声和背景噪声存在的情况下实现双耳目标声提取的神经网络
2.设计了一种能够使系统推广到真实世界使用的训练方法
结果:
- 系统能够处理20种声音类别
- 基于transformer的网络在连接的手机上的运行时间仅6.56毫秒
- 可以从以前未见过的室内和室外场景中提取目标声音并将其保留在双耳输出中
INTRODUCTION&BACKGROUND
为了满足人们想要听到特定的声音并屏蔽其他的声音,需要降噪耳机先消除所有声音然后将人们想听到的声音重新引入耳机,后者正是本文主要研究的内容。
实现专注于目标声音和关联的方向很有挑战的原因:
- Real-time requirements:目标声音输出需要和使用者的视觉感知同步,也就是需要实时处理并满足严格的时间延迟。
- Binaural processing:两个耳朵接收到的声音有不同的延迟和衰减,与头部相关的传递功能(HRTFs)为空间感知提供了线索,为了保留这些线索需要保留目标声音的空间信息。
- Real-world generalization:很难在仿真中充分捕获真实世界声音反响和HRTFs。
为了解决上述问题本文提出了第一种能够在干扰声和背景噪声存在的情况下实现双耳目标声提取的神经网络并设计了一种能够使系统推广到真实世界使用的训练方法。从用于目标声音提取的单通道transformer模型开始,针对手机上的实时操作优化了网络,然后设计了一个联合处理双耳输入信号的网络,使其能够保留空间信息。
得到的结果如下:
- 在20个目标声音中实现平均7.17dB的信号增益(在存在干扰声音和背景噪音的情况下),实时网络的运行时间为6.56ms来处理一个10ms的双耳音频块。
- 野外评估表明:我们的系统可以提取目标声音并推广到未见过的参与者和环境中而无需使用可穿戴设备收集任何训练数据。
- 参与者能够预测系统输出声音的方向,得到的误差与无噪声的干净声音类似
SEMANTIC HEARING
System Requirements
我们设计的目标是对声音环境进行低延迟的编程,达到目标声音存在、其他声音被抑制的目的。为了满足严格的延迟限制,我们必须使用手机等计算受限的设备进行实时操作,同时为了使生成的目标声音与来自于真实世界中的目标声音声源方向相同,因此设计必须满足实时低延迟操作和双耳真实世界推广的目的。
实时低延迟操作(Real-time low-latency operation)
端到端延迟的组成部分:
- 声音信号输入到双耳麦克风的两个记忆缓冲区
- 记忆缓冲区每块中的数据输入到神经网络中并输出块长的双耳目标声音数据
- 输出数据通过耳机上的两个扬声器播放
为了耳机中的声音与用户视觉感知同步,需要端到端延迟少于20-50ms。
双耳真实世界推广
目标声音在现实世界中经历反射、多路径传播以及人的头部躯干等对声波的反射和阻挡,因此目标声音到达双耳的延迟和振幅是不同的,进而双耳的差异为人类提供空间意识,因此在我们的设计中让两个扬声器以不同的振幅和延迟播放是很重要的。
Binaural target sound extraction network
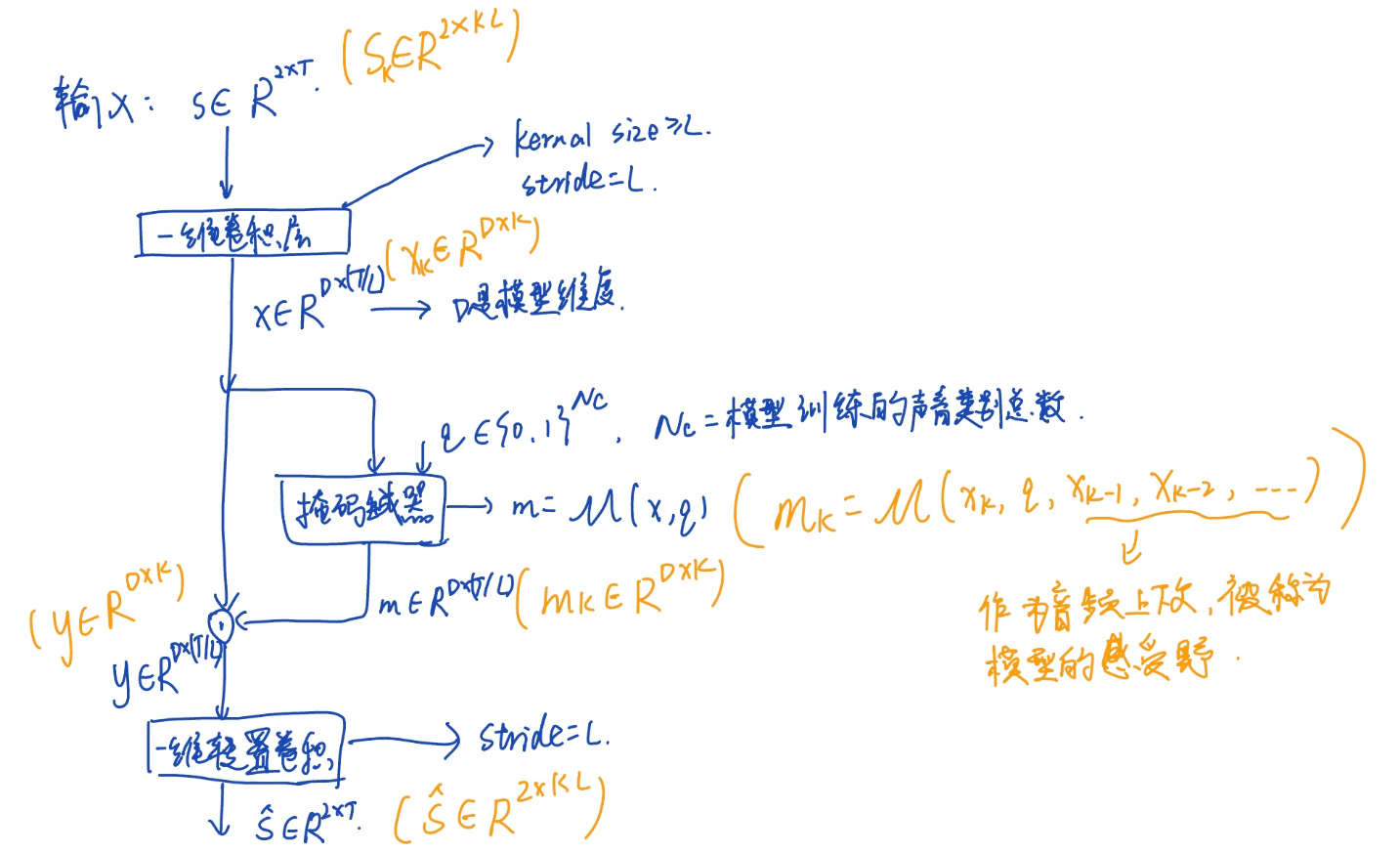
High-level framework
输入双耳信号:\(s \in R ^ { 2 \times T }\),输入信号首先通过一个1D卷积层(kernel size $\geq$ L,stride = L,其中D,L是可调超参数,D为模型维度,L决定了最小可以被模型处理音频块的持续时间) 被映射到潜在空间中\(x \in R ^ { D \times ( T / L ) }\), x然后被传递到掩码生成器\(M\)中,掩码生成器对x进行按位掩码输出m: \(m = M ( x , q ) | m \in R ^ { D \times ( T / L ) } ; q \in \{ 0 , 1 \} ^ { N _ { c } }\) (${ N _ { c } }$是模型训练的声音类别的总数),然后通过\(y = x \cdot m| y \in R ^ { D \times ( T / L ) }\)点乘运算得出目标声音的表示,最后y通过一个转置卷积层(stride=L)得到输出音频信号。
(掩码生成器:学习生成一种掩码,该掩码被应用到混合音频上,从而分离出单独的声音源。这里的“掩码”是指一个与输入音频相同维度的矩阵,其中的每个元素表示相应时间步的权重。通过将混合音频与这个掩码相乘,可以得到分离出目标声音源的音频信号。)
为了计算的高效性,我们的设计共同处理双通道
Streaming inference and causality(流式推理和因果关系)
(流式推理:是指在模型处理输入数据时,逐步进行、逐块完成的推断过程。与一次性将所有输入数据传递给模型并等待整个过程完成(批处理推断)不同,流式推断是逐个或逐批地处理数据,而无需等待所有输入都可用。)
因为音频从缓冲区被输入到模型中,因此缓冲区大小决定了模型每次收到音频块的持续时间。假设缓冲区大小可以被步长L整除,音频块可以被表示成步数K,也就是说大小为 K 的音频块的缓冲区大小等于 KL 个样本。这种实时设置意味着模型只能访问当前和前一个块,而不能访问未来块。这需要模型在缓冲区大小的时间分辨率 KL 音频采样上具有因果性。输入卷积,掩码估计块,逐元素乘法,转置卷积在每一个时间步中必须运行在一个音频块中。
上述框架可以适应块级流式推理。输入音频信号对应于第k个音频块\(s_{k}\),一维卷积层将其映射到隐藏空间表示\(x_{k}\)中,然后通过掩码估计模块基于当前块和之前的块估计对音乐目标声音的掩码,之前的块被称作模型感受野,当前块对目标声音的表示\(y_{k}\)可以通过\(x_{k}\)和\(m_{k}\)的点乘得到,\(y_{k}\)最后通过转置卷积层被转换成输出信号\(s_{k}\)。
Mask estimation network(*)
本文中采用一种对于Waveformer(高效的流式处理架构,实现基于块的处理)的改进版本,编码:纯卷积网络,解码:transformer 解码器,编码和解码的维度相同(使我们可以使用标准transformer解码器)。
编码器
为了缓解每次迭代重复处理整个感受野同时实现一个大的感受野,我们采用Wavenet风格扩张因果卷积来处理当前输入块和之前的块。使用Fast Wavenet中的动态规划算法通过重用之前迭代中计算的中间层结果实现高效率,编码函数通过处理输入块和一个编码上下文来生成输入块的编码表示。编码器由 10 层等间隔扩张因果卷积层堆叠而成,每个卷积层的kernel size都为3,从第一层开始,在每个后续层中的扩张因子会翻倍。由于核大小等于3,因此每个扩张卷积层所需的上下文是该层扩张因子的两倍。只要在每次迭代之后保存此上下文,并在下一个迭代中填充输入块,那么与前一个块对应的中间结果就不必重新计算。
解码器
目标声音对应的掩码通过使用transformer解码器来估计,查询向量\(q\)最初通过全连接层被嵌入到嵌入空间生成一个标签嵌入\(l\),通过按元素乘法将标签嵌入\(l\)条件地应用于编码表示,对编码表示进行条件处理。在transformer解码器处理之前,首先在时间维度上将编码表示和条件编码表示与来自之前时间步长的编码表示和条件编码表示连接。
首先使用第一个多头注意力模块计算条件编码表示的自注意力结果,然后使用第二个多头注意力模块计算自注意力结果和非条件编码表示,最后通过前馈块生成最终的目标声音对应的掩码。

Training for real-world generalization
Picking audio classes
AudioSet ontology(本体)提供了一个不同声音类别关系全面的结构化的表示,每个声音类别在树中为一个节点并且有一个唯一的ID,子节点则表示更加具体的声音,父节点表示相对广泛的声音类别。
目标声音类别
先考虑各种常见场景,然后识别出在这些场景中的声音源,然后把他们映射到AudioSet本体中的标签。最终选取了20个人们可以准确区分的声音类别。
其他声音类别
使用AudioSet分层结构和20类目标声音来生成141个其他声音类别集合,通过将AudioSet本体视为一个有向无环图,其边从每个声音类节点指向其子节点,我们将未知声音类定义为与所有目标声音类节点不相连的AudioSet节点集。
Audio dataset curation(管理)
组合4个不同数据集的音频样本并标准化类型标签(将类型标签映射到AudioSet中语义最接近的标签),同时对其中两个数据集进行预处理。然后把得到的音频样本分为每段15秒并丢弃无声部分。然后将数据集分别划分训练集、测试集、验证集,最后将它们合并到我们的最终数据集中。
Binaural data synthesis
为了创建双耳混合声音样本,我们使用了一个包含 43 个已有的头相关传输函数 (HRTF) 测量值的数据集并添加三个测量值和模拟值的混响双耳房间脉冲响应 (BRIR) 。从训练集中随机选取一个数据集和一个房间样本和参与者,然后为了创造k个声源的双耳混合物,我们为每个声源独立选择一个声源方向。然后获得一个2K个脉冲响应的集合并通过卷积操作计算左耳和右耳收到的声音。
Training procedure
使用Scaper工具包动态合成双耳混合物,每个混合物6秒长,来自目标和其他背景类别的声音3-5秒,背景城市声音则持续整个混合物的时间。同时为目标声源合成了基本事实信号。然后训练网络产生一对左右通道目标声音估计,并使用样本敏感和尺度敏感的信噪比独立应用并取平均到左右通道获得损失函数。
最后训练transformer模型迭代80次,在迭代40次后如果连续5次迭代以上SNR没有提高就将学习率减半。
RESULTS
In-the-wild evaluation
In-the-wild scenarios
3女2男共5名参与者佩戴硬件在典型的应用场景中收集声音,并选择了我们的录音中最常出现的类型子集。声源和参与者可以随意移动,更加模拟真实场景。
Evaluation procedure
进行听觉研究采用MOS度量声音提取的准确性,22个参与者参与本研究,研究分为16个部分,在每个部分中参与者评估通过以下三种方式处理的音频的质量:
- 原始录音
- 128维度双耳网络的输出
- 256维度双耳网络的输出
对于目标声音是说话的部分,还包括通过提取干扰类别然后从录音中减去的第四个样本。
我们根据干扰抑制和总体MOS(平均意见分数)两方面来衡量声音提取的质量。
Results
结果显示系统能够显著减少背景音。由图可以看出整体噪音抑制评分和MOS均有提高。当目标是语言的时候,通过从输入录音中去除干扰信号而不是直接提取语音可以提高整体MOS评分。(这些野外结果来自仅使用合成数据训练的模型,而没有对我们的硬件或参与者收集的数据进行任何训练)
Evaluating user-perceived spatial cues
Data collection
我们收集了来自已知方向的目标声音的真实世界音频录音。数据收集分为9个阶段每个阶段参与者被旋转到不同的角度,在每个阶段扬声器播放4个5秒音频样本分别为白噪声、属于目标声音类别的测试样本、属于干扰声音类别的测试样本。所选的音频样本确切地包括来自9个不同干扰其他声音类别的9个测试样本,以及来自6个不同目标声音类别的6个测试样本。(每个目标类别的测试样本分别在3个不同相对角度下录制)
Evaluation procedure
我们设计了一个用户研究来计算系统输出的目标双耳声音的感知到达角度。首先从目标类别中采样两个音频剪辑,从干扰其他类别中采样1-2个剪辑创建混合声音(使用Scaper生成),然后选择一个目标声音类别并将混合声音通过网络进行处理。并将没有干扰的单独清晰的目标声音录音和网络输出播放给同一组参与者(一个参与者的声音信号都源于他采集的),样本以随机顺序播放。在听取每个样本之前,参与者被告知他们应该定位的目标声音类别。听完后,他们被要求预测声源的方向。
Results
我们分别比较了目标声音记录中真实源方向与用户感知到达方向之间以及由我们的系统生成的双耳混合信号输入的目标声音信号的误差。平均角度误差略微从18度增加到23.25度。此外,我们观察到插值的第50和90百分位误差也分别从5度增加到9度和从38度增加到42度。这表明我们的模型在其输出中保留了目标声音的空间线索,并对用户感知源方向几乎没有影响。
Integration with noise canceling headsets
用户戴一副主动降噪的耳机,在耳罩内戴双耳麦克风,用于记录由主动降噪和语义听觉系统共同产生的声音。(用户听到的声音)
结果得出系统可以抑制不需要的声音,同时保留目标声音,说明系统可以与主动降噪系统共存。(from figure12)
未来可能工作:为了减轻残留噪声,语义听觉子系统可能需要集成降噪耳机中的残留音频,以适应回放信号以匹配残留噪声。 然而这带来了更严格的延迟要求。
Benchmarking(基准测试) the neural network
我们在一个包含10000对混合和地面真实的广泛混响双耳测试集上评估我们的模型。为了评估双耳提取模型的性能,我们比较了三种双耳目标声音提取框架:
- 双通道架构:双耳信号在进行掩蔽估计之前被转换成一个联合潜在空间表示,左右声道都被合并成一个共同的表示。
- 并行处理架构:实现了左右声道的并行处理,并在声道之间进行了一些交叉通信。
- 单通道架构:应用于左右声道的模型参数是相同的,声道之间没有交叉通信。
对于每个模型,我们比较了信号质量、空间线索准确性和设备上运行时间要求。
- 信号质量:SI-SNRi(尺度不变的信噪比改进)来衡量
- 空间线索准确性:输出双耳信号和地面真实双耳信号之间的双耳时间差(ITD)和双耳强度差(ILD)来衡量
- 运行时间要求:在100次迭代中平均计算10毫秒大小的输出块的运行时间来衡量
当仅使用SNR损失进行训练时,因果Conv-TasNet会收敛到生成一个常数零信号的局部极小值。所以建议使用90%的SNR + 10%的SI-SNR损失来训练Conv-TasNet。
由表2:双通道框架在SI-SNRi方面与并行和单通道框架差不多,而在ΔILD方面表现优越。并行和单通道框架具有独立处理不同通道的分支,有助于保持与各自通道的样本对齐,在单通道框架中更为显著,其中SI-SNRi和ΔITD表现出色,但ΔILD较差,因为左右声道处理之间没有交叉通信。最后,我们注意到我们的双通道框架的运行时间仅需其并行或单通道对应物所需时间的50%多一点。
表4提供了在听众和声源之间不同相对角度运动量下性能的定量比较,对于这个比较,我们使用256 维的双通道模型。使用Steam Audio SDK模拟运动,在消音和混响环境中进行了不同角速度的控制实验,其中声源从弧形上的随机位置以给定的角速度移动,通过在每个帧上使用双线性插值卷积插值的插值脉冲响应,以250毫秒的块计算 ΔILD 和 ΔITD,丢弃在这两个通道上干净的信号都是静音的块,并在剩余的块上取均值。观察到,在运动存在的情况下,由于模型能够更好地利用在不同相对角位置处左右之间的电平差异,SI-SNRi 和 ΔILD 稍微更好,而在消声情况下 ΔITD 较低,在混响情况下 ΔITD 稍微更高。
Proof-of-concept user interface
我们设计了一个原型iOS应用,提供了三种不同的用户界面供声音选择:语音、文本和切换开关声音网格。
十名参与者每人被呈现十个场景,我们要求参与者选择一个要添加或删除的单一声音事件,并通过三种用户界面(UI)传达他们的意图给应用。为了评估每个界面的准确性,我们将通过每个界面选择的声音事件与我们对用户说的内容的最佳解释进行比较。语音和文本的一致率为92%,切换开关为93%。对于语音和文本,不一致是由于ChatGPT的混淆或者当其将数据集中没有的选定声音映射到数据集中类似的声音时发生的。对于切换开关,不一致发生在无法找到预期声音类别时。
传达意图所需平均时间:语音<切换开关<文本
偏好评分:切换开关<文本<语音
LIMITATIONS AND DISCUSSION
- 各类别声音样本数量不平衡
- 一些类别可能本质上更难分离,将音乐与其他类别分离也可能具有挑战性
- 收集真实世界场景和实际硬件的训练数据有可能提高系统性能
- 在评估中使用的可穿戴硬件的外形因素也是一个限制
- 双耳目标声音提取还可以用于减去目标声音并将剩余声音播放到耳朵中
- 将我们的系统扩展到无线耳机需要将计算与耳机硬件本身集成
- 商业化的语义听力设备用于语义听觉可能会使用这样的自定义硅来降低可穿戴设备的功耗和端到端延迟
CONTRIBUTION
- 提出第一个可以在干扰和背景噪音存在的情况下进行双耳目标声音提取的神经网络,并证明此网络可以在手机上实时运行
- 设计了一种能够使系统推广到以前未见过的真实世界使用的训练方法
- 在现成的硬件上进行了概念验证,展示了我们系统在真实环境中实现上述目标
- 强调了当前系统的局限性以及未来研究的机会
- 公开模型和数据集,希望推动未来研究和进一步发展