
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
ICLR 2021
Abstract
虽然transformer在nlp领域已经应用广泛成为标准架构,但是其在CV领域应用仍然有限。本文证明了纯transformer而不用CNN来处理一系列image patch的效果在图像识别领域效果很好。尤其在大规模数据集上进行预训练随后应用于中小型数据集上的效果可以与CNN的sota媲美。同时本文挖了很多坑包括多模态、自监督,视觉领域的其他任务、改tokenization等。
Artrcture
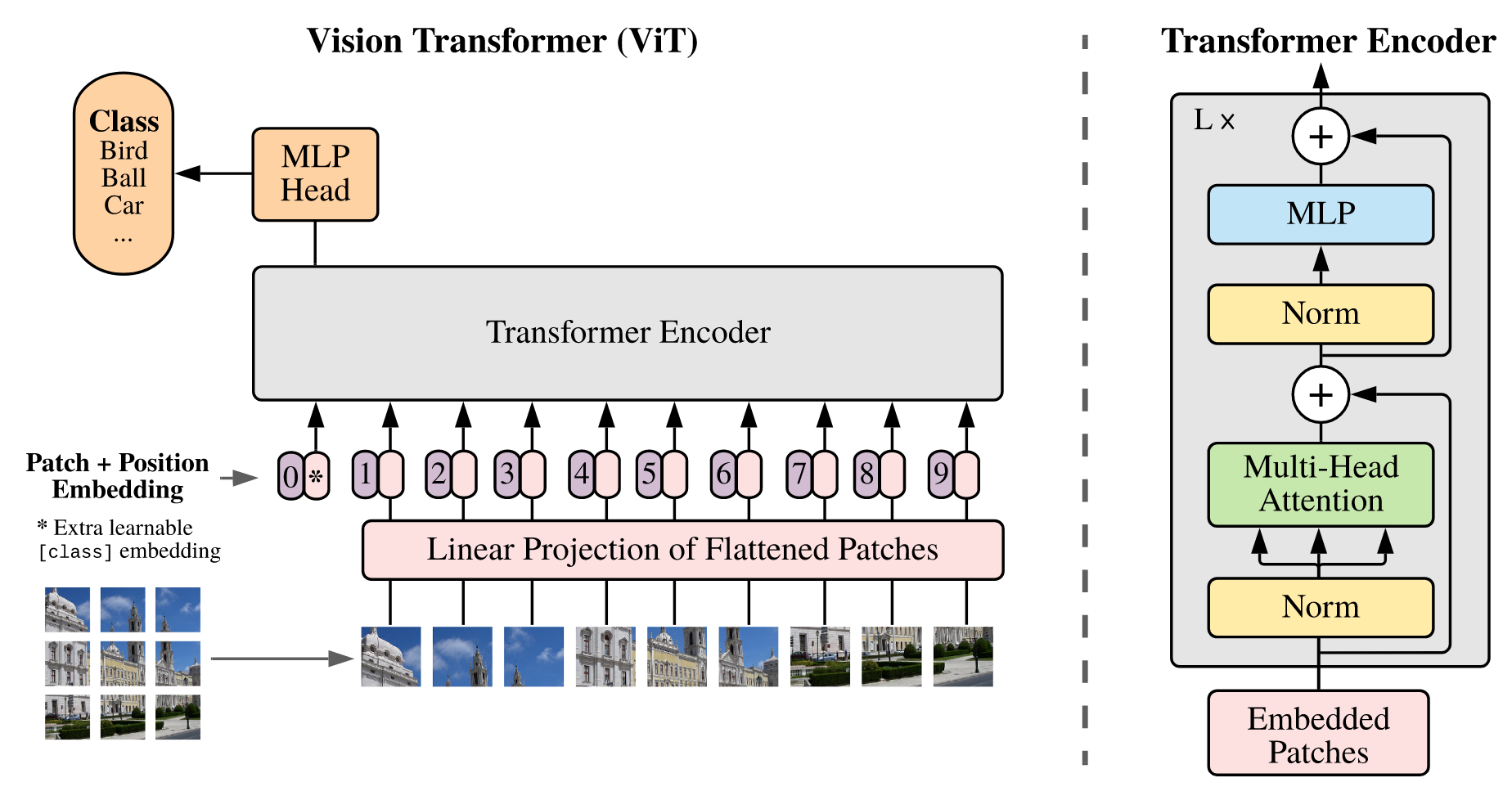
首先将输入图像分割成image patch,然后将所有的patch弄成一个序列并通过线性层得到特征(patch embedding)并加入patch之间的位置信息(position embedding)。随后将得到的token输入到transformer encoder中得到模型输出。借鉴BERT引入特殊字符cls,该字符的位置信息为0,由于所有的token会进行交互,所以认为只根据cls的输出做最后的分类,通过交叉熵进行最后的分类。
Experiment
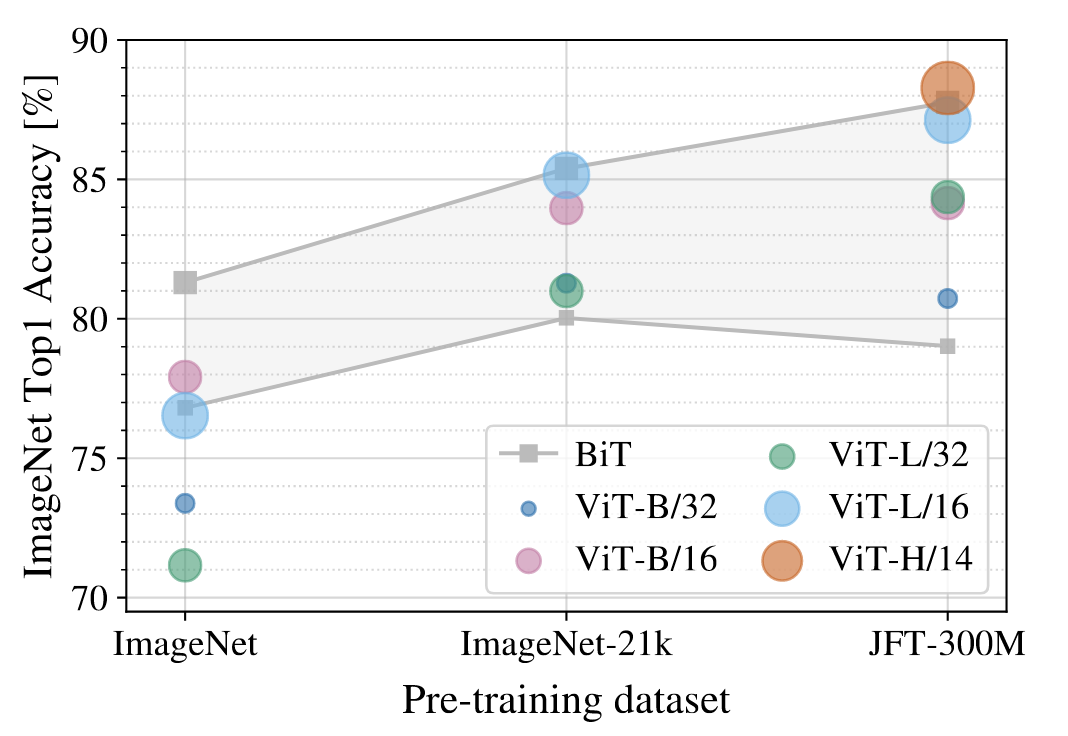
- 使用了ImageNet-1k,ImageNet-21k、JFT等数据集
- fig3展示出ViT在中小型数据集上的效果上不如BiT的,这是因为ViT没有用到过多的先验知识,所以需要更多的数据使得模型训练效果更好。但是在巨型数据集时ViT超过了BiT模型的效果。
- nlp领域可以用transformer进行大规模的自监督训练,而ViT用的是有监督训练,本文也同时尝试通过masked patch prediction进行自监督训练,但是实现的效果和有监督训练相比效果不是特别好。
Others
- transformer应用到CV的难处,如何将2D图像看成1D的sequence(如果每个像素点当成一个元素的话序列长度会无敌长,之前有用特征图当作输入、用原始图像的一个local window、在H和W上拆分做两次自注意力等)。
- inductive bias(归纳偏置):指一种先验知识或者提前做好的假设,比如在CNN中两个常见的inductive:locality(相邻的区域会有相似的特征)和translation equivalence(平移等变性,先做卷积还是先做平移得到的结果是一样的)
- intro部分思路梳理:先说了transformer在NLP扩展性很好,越大的数据集越大的模型得到的模型效果会一直上升不饱和。自然出现问题,应用到CV中是不是也会这样。随后讲了前人的工作(讲清楚自己的工作和前人的工作区别在哪),说了之前的工作没有直接把transformer应用过来并且都没有得到很好的扩展效果。随后说了本文的做法,也就是直接应用transformer,将CV问题按照NLP问题进行考虑,将图像分为小的patch处理。最后讲一下模型的结果。
- cls:是一个可学习的特征,和图像patch的特征维度相同,只有一个token,也就是1*C,并将其通过transformer encoder得到的特征视为最后的图像特征进行分类。 其实也可以不用class token,可以将transformer encoder得到的输出进行globally average- pooling(GAP)操作得到图像的整体特征,但是作者为了尽可能的与原始transformer保持一致,引入了cls token。
- positional embedding:本文使用的是1-dimensional positional embedding,也可以使用2D positional embedding或relative positional embedding,得到的效果差不多。
- image patch能不能重叠,这样是不是可以不用加入位置信息了,以及在应用于其他大小的image上可以直接拿来用。