
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
ICML 2021
Abstract
视觉语言预处理VLP在很多视觉和语言下游任务上取得了很好的效果,之前的方法很依赖于图像特征提取过程和CNN。作者发现这些主流方法存在效率问题并且表达能力受限。因此作者在本文提出一个极小的VLP模型,处理视觉输入的过程简化为与处理文本输入相同的无卷积方式,比之前的VLP模型快了不止10倍,同时模型效果和之前的类似或更优。
Artrcture
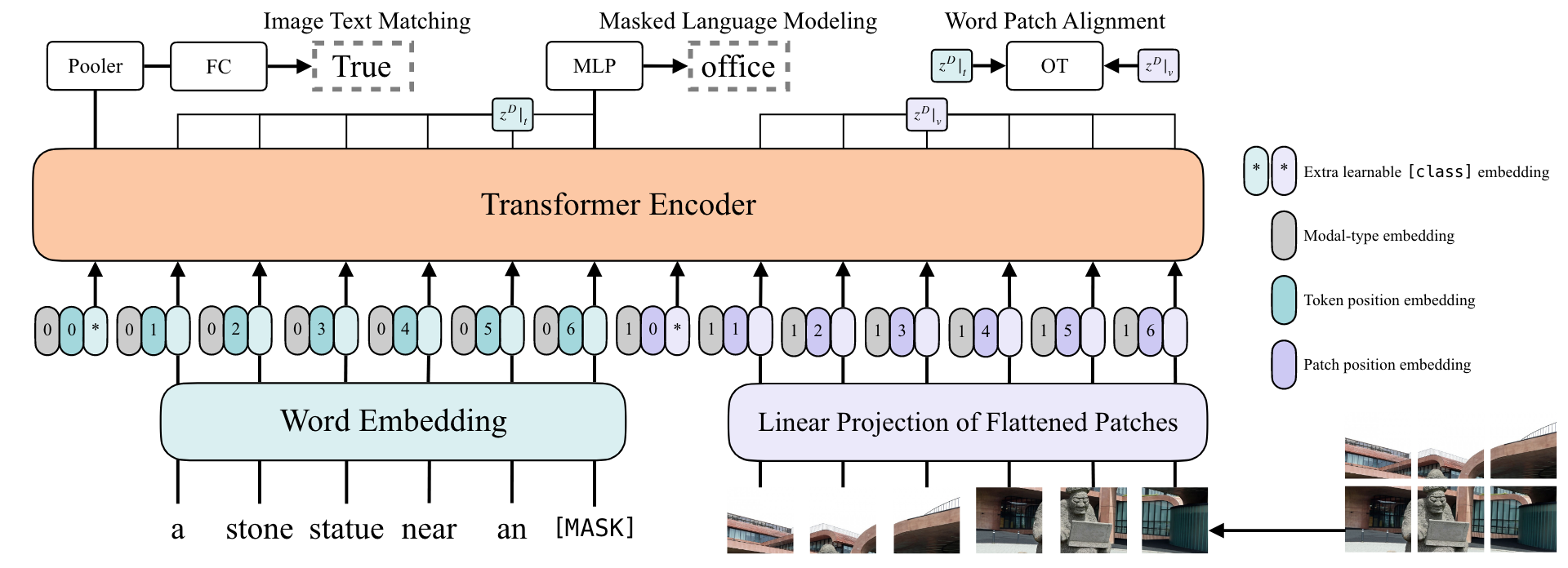
- 使用single-stream方法,灰色的embedding用于区分特征是来自文本还是图像。图中的三种embedding是加在一起的而不是concat到一起。
- input:文本特征部分shape为LxH,L表示token的数量,H表示一个token的长度;图像特征部分shape为NxH,N表示图像patch的数量。整体特征shape为(L+N+2)xH,2是两个模态起始cls token。
- loss:采用image text matching和masked language modeling两个损失函数,以及一个word patch alignment函数。
- Whole Word Masking:mask掉组成一个单词的所有连续子token,举例来说,针对单词giraffe,由三个子token:“gi”,“raf”,“fe“组成,如果只mask掉中间的raf,那么很容易不通过图像信息就能预测出中间的子token,为了避免这种情况发生,使用whole word masking这种技巧。
- Image Augmentation:应用RandAugment,但是为了避免图像增强后文本和图像的匹配出现问题,不使用color inversion和cutout。极大程度上保证了增强后图像和文本仍能匹配上。
Experiments
- 数据集(4million):MSCOCO(每个图像对应5个标题,每个标题长度平均10个单词),VG(每个图像对应很多标题,每个标题长度较短),GCC(一个图像对应一个标题,标题长度较长),SBU(一个图像对应一个标题,标题长度较长)
- VQA&NLVR:时间上均快了很多倍,在VQA上效果与Region方法相近,在NLVR上效果比一部分Rigion方法更好,和sota相比差一些。
- Image Retrieval:在zero-shot方面和fine- tuning方面分别进行实验,得到的实验结果与上述类似,可以在效率和模型表现上得到一个很好的tradeoff。
- ablation:分别加入whole word masking,RandAugment,MPP(在图像部分进行mask),得到最佳组合并训练更多的steps得到最佳结果
Others
- VLP模型主流的两个目标函数为图像文本匹配和MLM(masked language modeling)
- 预训练微调模式中,预训练过程会花费更多的资源和开销,甚至一些预训练模型可以zero shot应用到下游任务中
- 目前大部分VLP模型尝试通过提升视觉编码器的性能来提升模型表现,而忽略了运行速度、效率等问题,这也是本文的一个主要卖点
- suggestion:初入一个领域时可以考虑写一篇综述文章,对现有方法进行总结归纳。
- 现有模态融合方法分为两种:single-stream approaches(将两个输入序列concat到一起,用一个模型处理),dual-stream approaches(两个模型先各自对单个模态输入进行处理,在后续的某个时间点再进行交互)。