
Attention Is All You Need
NIPS 2017
参考:https://www.jintiankansha.me/t/RcTuLXkjul
Abstract
旧问题新技术,提出一种完全基于注意力机制的transformer架构,不使用CNN和RNN,并行度很高。 优点:计算高效,上下文相关性的建模能力强
知识概述
-
One-Hot Encoding:在 CV 中,我们通常将输入图片转换为4维(batch, channel, height, weight)张量来表示;而在 NLP 中,可以将输入单词用 One-Hot 形式编码成序列向量。向量长度是预定义的词汇表中拥有的单词量,向量在这一维中的值只有一个位置是1,其余都是0,1对应的位置就是词汇表中表示这个单词的地方。优点是简洁,缺点是很稀疏,如果词很多的话向量会很长,并且无法体现出词与词之间的关系。
-
残差连接:\(F(x) = F(x)+x\),在对x求偏导的时候多了一个常数项1,所以在反向传播过程中不会造成梯度消失。
-
Layer Normalization:对每个样本在同一层内的所有特征进行归一化,而batch normalization是对每个小批次数据的同一维度的特征进行归一化。
-
Word Embedding:传统的 one-hot 编码无法捕捉单词之间的语义关系,因为每个单词都被表示为独立的、稀疏的向量。Word embedding 通过将单词映射为密集的向量,使得语义相近的词(例如 “king” 和 “queen”)在向量空间中更接近,从而能够反映单词间的语义相似性,同时还能起到降维的效果。通过设计一个可学习的权重矩阵W,将词向量与W进行点乘,得到新的表示结果即为Word Embedding。
-
Positional Encoding(使用的绝对位置编码):经过 word embedding,我们获得了词与词之间关系的表达形式,但是词在句子中的位置关系还无法体现。由于 Transformer 是并行地处理句子中的所有词,因此需要加入词在句子中的位置信息,结合了这种方式的词嵌入就是 Position Encoding。即预定义了一个函数,通过函数计算出位置信息。
\[P E _ { ( p o s , 2 i + 1) } = \cos ( p o s / 1 0 0 0 0 ^ { 2 i / d } )\]
\(P E _ { ( p o s , 2 i ) } = \sin ( p o s / 1 0 0 0 0 ^ { 2 i / d } )\)pos代表词在句子中的位置,d是词向量的维度(通常通过word embedding后是512),2i表示是d中的偶数维度,2i+1代表奇数维度,这种计算方式使得每一维都对应一个正弦曲线。
-
encoder:将\(x = (x1, x2, ... , xn)\)(原始输入)映射成\(z = (z1, z2, ..., zn)\)(机器学习可以理解的向量)
-
decoder:给定z,生成一个输出序列\((y1,y2,...ym)\)(n和m可以一样长也可以不一样长),只能一个一个生成。
-
auto-regressive:过去时刻的输出又作为当前时刻的输入
-
attention机制:q、k、v分别表示query、key、value,输出为一个value的加权和,权重等价于query和对应key的相似度
-
Scaled Dot-Product Attention:对query和所有的key进行点积得到值,再对点积结果除以\(\sqrt{d _ {k}}\),完成scale;在scale之后进行mask,目的是当t时刻的query只能看到k1到kt-1;再通过softmax获得每个value对应的权重,最后和value加权求和得到输出向量。
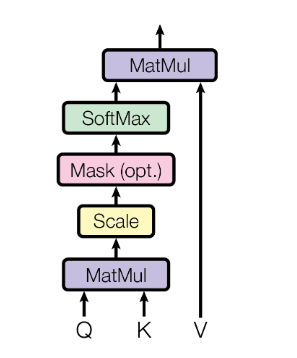
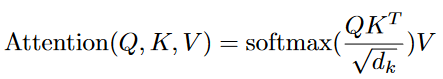
当\(d _ {k}\)较大时,向量之间的点积结果非常大,会造成softmax函数陷入到梯度很小的区域,不利于反向传播,因此设置缩放因子\(\sqrt{d _ {k}}\)对点积结果进行尺度化,将其缩小到梯度敏感的区域内。当\(d _ {k}\)较大时使用Additive attention比较好,Additive attention可以处理q和k不等长的情况。
-
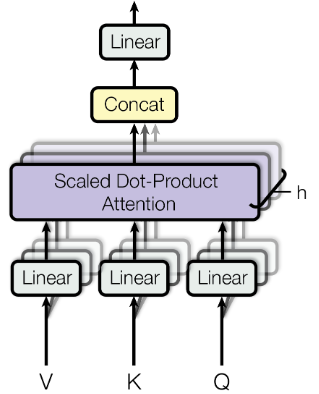
Multi-Head Attention:h次机会学习不同的投影方法,分别做点积再拼接到一起做一次投影。在base model中,将d_model=512维度的向量转换成n_head=8个64维度的向量,这样每个注意力头都有独立的64维度的表示。将输入表示投影到多头注意力机制的多个子空间中,从而能够捕捉不同的注意力模式。
- padding mask:在所有scaled dot-product attention都要用到,由于每个批次输入序列长度不同,所以需要对其进行对齐,也就是在较短的序列后面填充0,而在attention应该忽略这些位置,因此把这些位置的值加上一个非常大的负数,这样的话经过softmax后这些位置的概率就会接近0。而padding mask实际上就是一个张量,每个值都是bool值,值为False的地方为实际处理的地方,值为True的地方表示需要忽略的位置。
- sequence mask:只在decoder中的self-attention用到,为了使decoder不能看到未来的信息,也就是对于一个序列,在时刻t,decoder的输出应该只依赖于该时刻之前的输出,而不能依赖t时刻之后的输出,所以需要通过sequence mask把t时刻之后的信息抹去。具体做法是产生一个上三角矩阵,上三角值全为1,对角线和下三角值为0。
Architecture
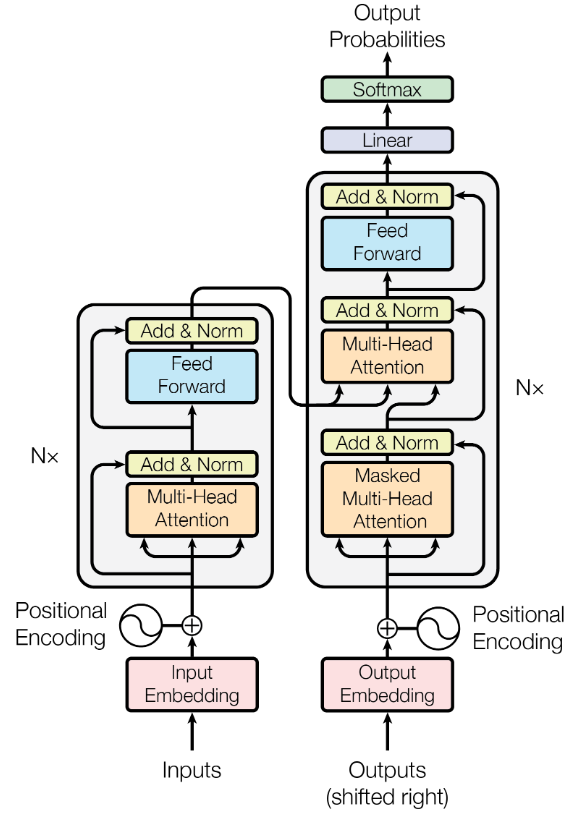
Encoder
由六个相同的层堆叠而成,每层由一个多头自注意力块和一个位置全连接前馈网络组成,在子层之间采用残差连接和正则化。
-
多头自注意力块
-
位置全连接前馈网络:线性层+ReLU+线性层
-
残差连接:每个子层的输出为该子层的输入和输出之和,要求每个子层的输入和输出维度相同。(训练的时候可以使梯度直接走捷径反传到最初始层)
-
正则化(Layer Normalization):在把数据送入激活函数之前进行,将数据归一化为均值位0,方差为1的数据(加快训练速度,加速收敛的作用,同时也可以避免梯度消失和梯度爆炸的问题)。Batch Normalization更适用于CNN处理图像,Layer Normalization更适用于序列化模型。
-
Feed Forward:前馈神经网络,先将dimension提升到d_ff,经过relu激活函数再降维 \(F F N ( x ) = \max ( 0 , x W _ { 1 } + b _ { 1 } ) W _ { 2 } + b _ { 2 }\)
Decoder
由六个相同的层堆叠而成,与encoder相比多一个掩码多头注意力机制。
- 掩码多头自注意力块:让t时刻不会看到t时刻之后的输入而只能看到之前的输入(也就是过滤掉t时刻之后的数据)。
- encoder-decoder多头注意力块:key和value来自于encoder的输出,query来自decoder下一个attention的输入,也就是掩码多头注意力块的输出。
- 前馈神经网络