
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
ICCV 2021 best paper
Abstract
提出一个新的应用到视觉领域的基于Transformer的架构叫做Swin Transformer,该架构可以应用到视觉领域的很多任务上。为了解决视觉实体的规模差异很大以及图像中的像素分辨率较高等问题,提出分层的transformer,特征表示是通过移动窗口计算的。通过将自注意力计算限制在不重叠的局部窗口内并允许跨窗口的连接来提高效率。这种分层架构关于图像大小具有线性的计算复杂度,此外移动窗口的方法对于MLP架构也有帮助。
Architecture
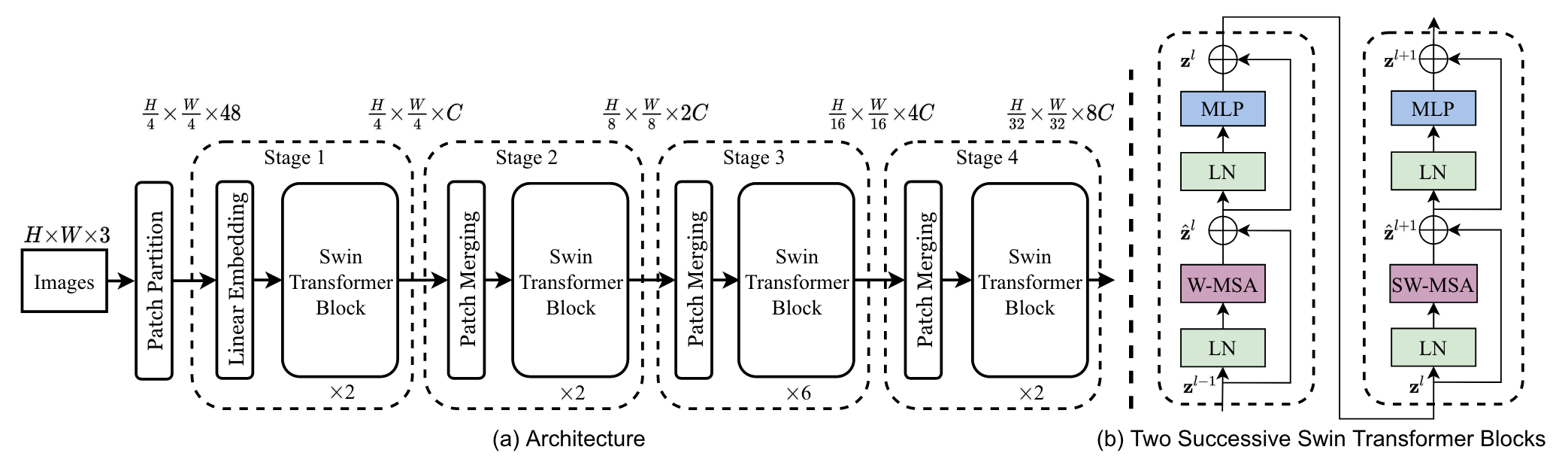
-
首先进行patch partition和linear embedding,相当于ViT中的patch projection步骤。
-
swin transformer block:基于窗口算自注意力,一个基本单元由一个基于窗口的自注意力和一个基于移动窗口的自注意力组成。
-
patch merging:类似于pixel shuffle上采样的反过程,把临近的小patch合并成大patch达到下采样特征图的效果。
举例如下:希望下采样两倍,那么每隔一个点进行采样,并将得到的特征图按照通道维度拼接到一起,得到H/2xW/2x4C,为了与卷积的操作一致,再在通道维度上通过1x1的卷积将4C降到2C,最终将原始HxWxC的张量变成H/2xW/2x2C的张量。

-
shifted window based self-attention:将图像划分成nxn个不重叠的相同大小的window,每个window里面有mxm个patch,自注意力的计算都是在window里面进行的,而序列长度永远为nxn。这种方式虽然很好地解决了内存和计算量的问题,但是窗口和窗口之间没有通信因此达不到全局建模,于是提出移动窗口的方式,把窗口往右下移一半,如下图所示。先做一次基于窗口的自注意力,然后做一次基于移动窗口的自注意力,达到全局建模的目的。
-
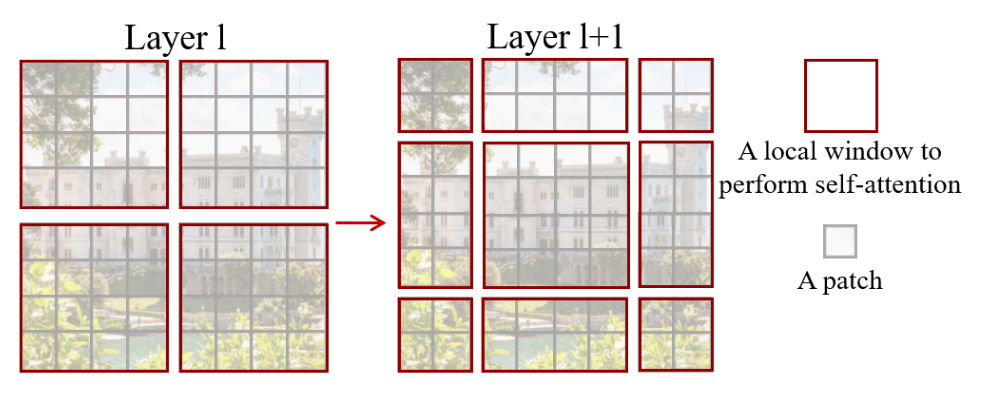
-
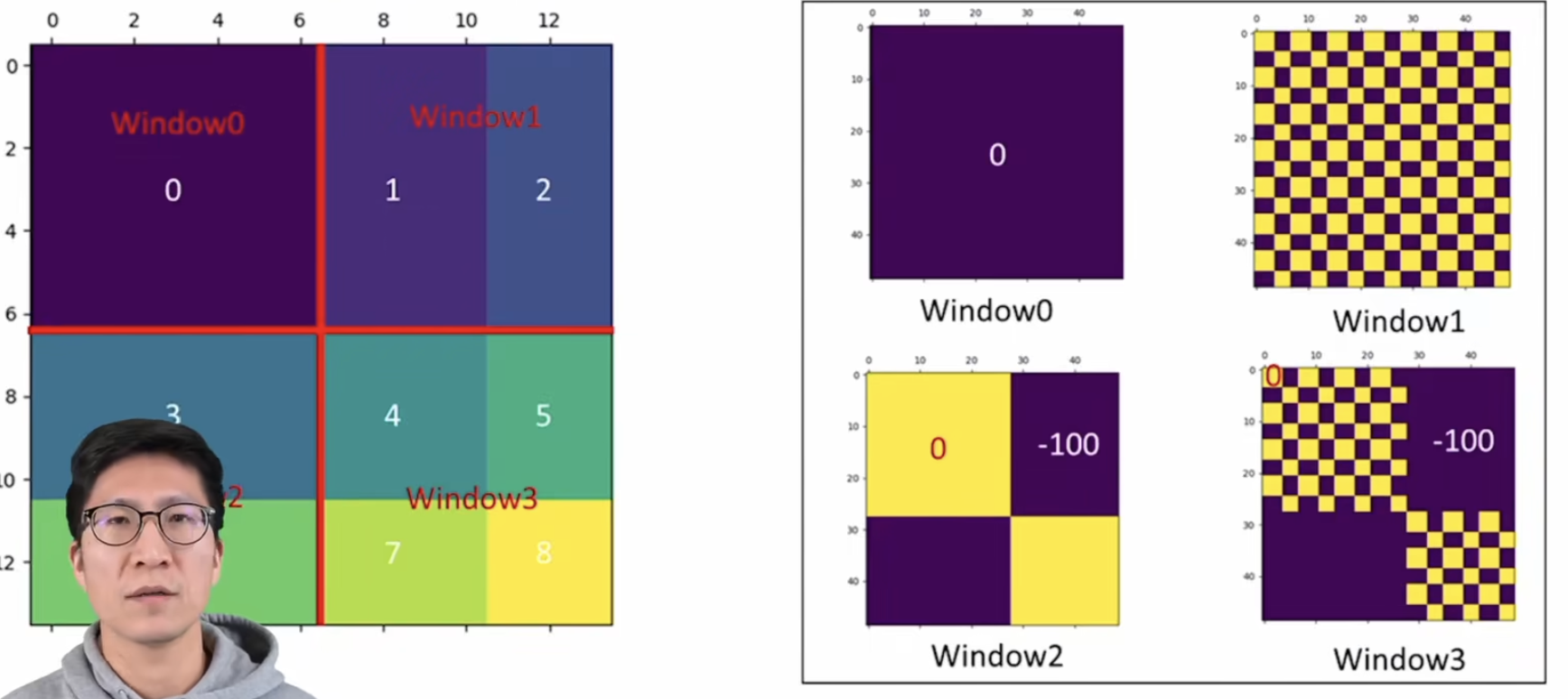
因为现在的移动窗口方法会将原来的4个窗口变成9个,不利于批次计算,因此再进行一次循环移位把9个窗口变成4个窗口如下图,随后通过巧妙的掩码使得移动后的patch直接可以合理的计算自注意力,计算后再将ABC还原到原来的位置。
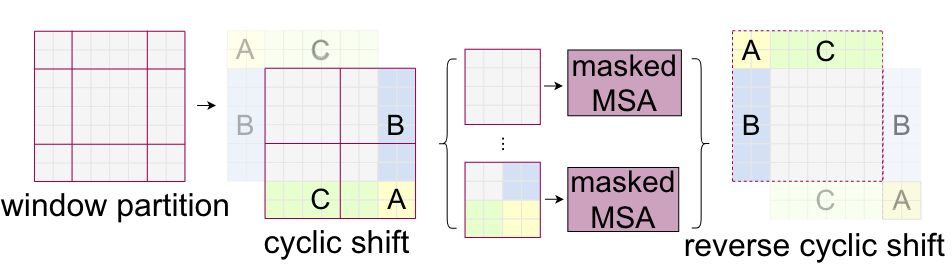
掩码操作:
Others
- ViT只在图像分类这个任务上展示了transformer的潜力,而Swim Transformer可以用到所有视觉任务上
- 对于视觉任务,多尺度的特征是很重要的,ViT中使用的是单一尺寸的低分辨率特征