
THE SPEECHTRANSFORMER FOR LARGE-SCALE MANDARIN CHINESE SPEECH RECOGNITION
ICASSP 2019
Abstract
在SpeechTransformer的基础上提出了三个优化策略,分别是使用更低的帧率、调度采样和聚焦损失。
Much Lower Frame Rate(LFR)
LFR背景:在语音识别系统中,语音信号通常会被分割成许多小的时间帧,每一帧都会被提取出特征(例如 Mel 频率倒谱系数,MFCC)。传统的语音识别系统会以较高的帧率(例如每秒100帧)处理这些特征。然而,较高的帧率会导致大量的计算开销和复杂性。为了降低计算复杂度,LFR 建模通过减少特征帧的数量来实现目标。通过减少输入特征的帧率,LFR 降低了模型的计算复杂度,从而加快了训练和推理的速度。
在Transformer中共出现三种attention,encoder self-attention、decoder-attention、encoder-decoder attention。self-attention将输入序列的不同位置联系起来,encoder-decoder attention使得decoder中的每个位置都可以考虑输入序列的所有位置。这三种attention的计算开销都由输入序列的长度决定,因此第一种优化策略就是降低输入序列的长度,即使用更低的帧率。
实现方法:在提取和堆叠特征后降采样到指定帧率。
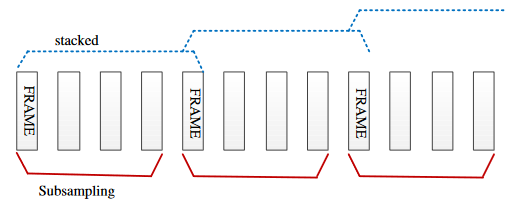
优势:提高计算效率、使得encoder self-attention更容易(产生更稀疏但信息更丰富的特征)、有利于encoder-decoder attention(减小序列长度了)。
Scheduled Sampling
背景:在训练序列到序列模型时,模型的输入通常是由实际的序列数据(ground truth)构成的。这意味着在每一步预测时,模型会使用之前的实际输出作为当前步的输入。然而,在推理时,模型只能依赖它自己在之前步骤中的预测结果作为当前步的输入。这种训练和推理之间的差异称为训练-推理不匹配(training-inference discrepancy)。Scheduled Sampling是一种训练策略,用于解决序列到序列(sequence-to-sequence)模型在训练和推理(测试)时的分布不匹配问题。
原理:核心思想是逐渐将模型从依赖实际序列数据的训练转变为依赖自己预测结果的训练。具体来说,在训练过程中,模型在每一步有一定概率选择使用自己前一步的预测结果作为当前步的输入,而不是实际的序列数据。这个概率会随着训练的进行逐渐增加,使得模型逐步适应依赖自己的预测结果。
在本文引入了三种提高采样概率的调度方案:
-
Linear: \(\varepsilon _ { ( i ) } = \min ( \varepsilon _ {\max } , \varepsilon _ { \max } \cdot \frac { i - N _ { s t } } { N _ { e d } - N _ { s t } } )\)
-
Exponential: \(\varepsilon _ { ( i ) } = e x p ( \frac { \log ( 0 . 0 1 ) } { N _ { e d } - N _ { s t } } ) ^ { \ \ \max ( N _ { e d } - i , 0 . 0 ) }\)
-
Sigmoid: \(\varepsilon _ { ( i ) } = 1 . 0 - \frac { N _ { e d } - N _ { s t } } { e x p ( ( i - N _ { s t } ) / ( N _ { e d } - N _ { s t } ) ) + ( N _ { e d } - N _ { s t } ) }\)
其中\(0 < \varepsilon _ {\max} \leq 1\)是采样预测的最大概率,\(N _ { s t }\)是应用调度采样的起始step,\(N _ { ed }\)是达到\(\varepsilon _ {\max}\)的step,\(i\)表示当前的step,\(\varepsilon _ { ( i ) }\)表示当前step的采样率。
Focal Loss
背景:Focal Loss 是一种在处理类别不平衡问题时特别有效的损失函数,核心思想是减小易分类样本的损失贡献,增强难分类样本的影响,从而提升模型在不平衡数据集上的表现。
训练数据中的字符频率分布不均匀,语料库中大部分token由少量的高频字符组成,然而还有很多低频字符。为了缓解这个问题,将焦点损失引入到训练过程中。 \(F L ( p _ { t } ) = - \alpha _ { t } ( 1 - p _ { t } ) ^ { \gamma } \log ( p _ { t } )\) 其中\(p _ { t }\)是模型对正确类别的预测概率,\(\alpha _ { t } \in [0, 1 ]\)表示加权因子,用于平衡正负样本的影响,\(\gamma \in \left[ 0 , 5 \right]\)表示可调焦距参数,用于调节易分类和难分类样本的影响。
当样本容易分类时(\(p _ { t }\)接近1),聚焦因子\(( 1 - p _ { t } ) ^ { \gamma }\)会趋近于0,从而减少该样本的损失贡献;
当样本难分类时(\(p _ { t }\)远小于1),聚焦因子\(( 1 - p _ { t } ) ^ { \gamma }\)会趋近于1,从而增强该样本的损失贡献。