
SPEECH-TRANSFORMER: A NO-RECURRENCE SEQUENCE-TO-SEQUENCE MODEL FOR SPEECH RECOGNITION
ICASSP 2018
Abstract
将Transformer应用到语音识别领域,此外提出2D-attention,能够同时考虑二维语音输入的时间轴和频率轴。
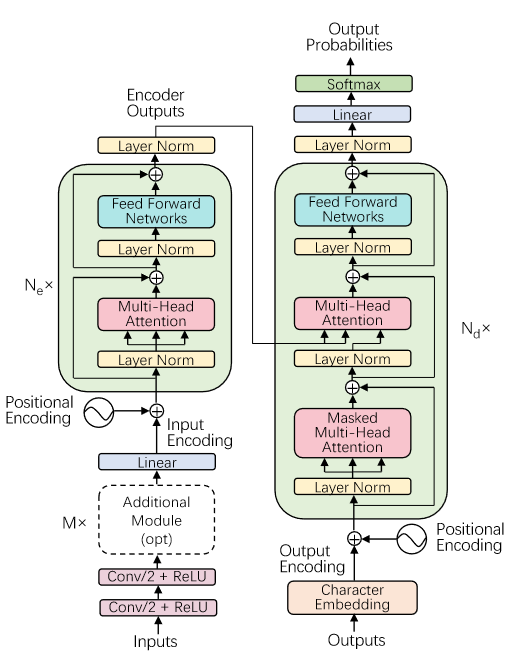
Architecture
整体框架与标准transformer无大差别,因此不再赘述,在这里只介绍一下新提出的2D-attention。
2D attention
语音特征序列通常被转化为同时具有时间轴和频率轴的二维谱图,并依靠不同频率之间随时间变化的相关性预测发音,因此提出2D-attention模块同时融入了时间信息和频率信息。
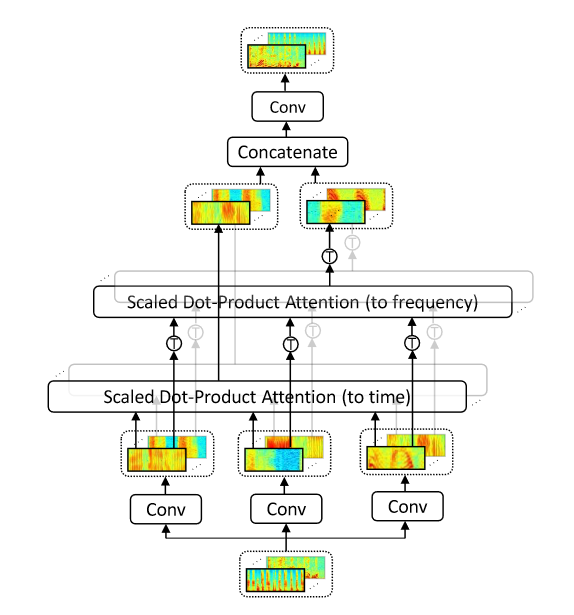
具体实现为:首先通过CNN提取出Q,K,V,通道数均为c。随后通过c个Scaled Dot Product Attention模块提取时间信息,通过c个Scaled Dot Product Attention在Q,K,V转置的基础上提取频率信息,最后将二者concatenate到一起通过CNN得到最终提取特征。
Conclusion
整体而言是第一篇将transformer应用于语音识别领域的成果,展示出transformer强大的能力,为后面该领域的发展奠定了基础。