
OVANet: One-vs-All Network for Universal Domain Adaptation
ICCV2021
Abstract
通用领域自适应UNDA旨在解决两个数据集之间的领域转变和种类转变,主要挑战在于拒绝源数据中不存在但在目标数据中存在的“未知”类。现有方法基于验证或预定义的未知样本比例手动设置阈值来拒绝未知样本,本文提出一种使用源样本来学习阈值并将其适用于目标域的方法。作者的想法是,在源域中,最小的类间距离应成为在目标域中决定“已知”还是“未知”的良好阈值。为了学习类间距离和类内距离,使用带标签的源数据为每个类训练一个一对所有(one-vs-all)的分类器。然后,通过最小化类熵来将开放集分类器适应于目标域。
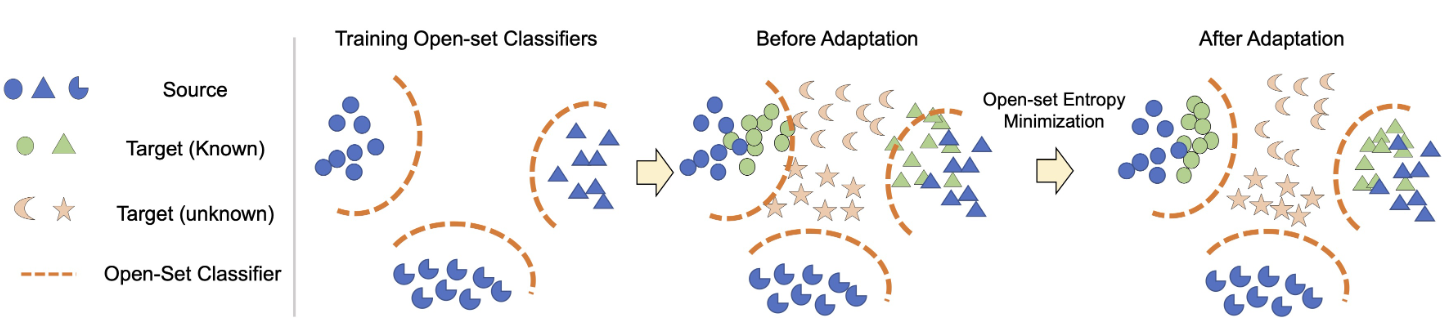
Background
DA
Domain Adaptation是一种源任务和目标任务一样,但是源域和目标域的数据分布不一样,并且源域有大量的标记好的样本,目标域则没有(或者只有非常少的)有标记的样本的迁移学习方法。
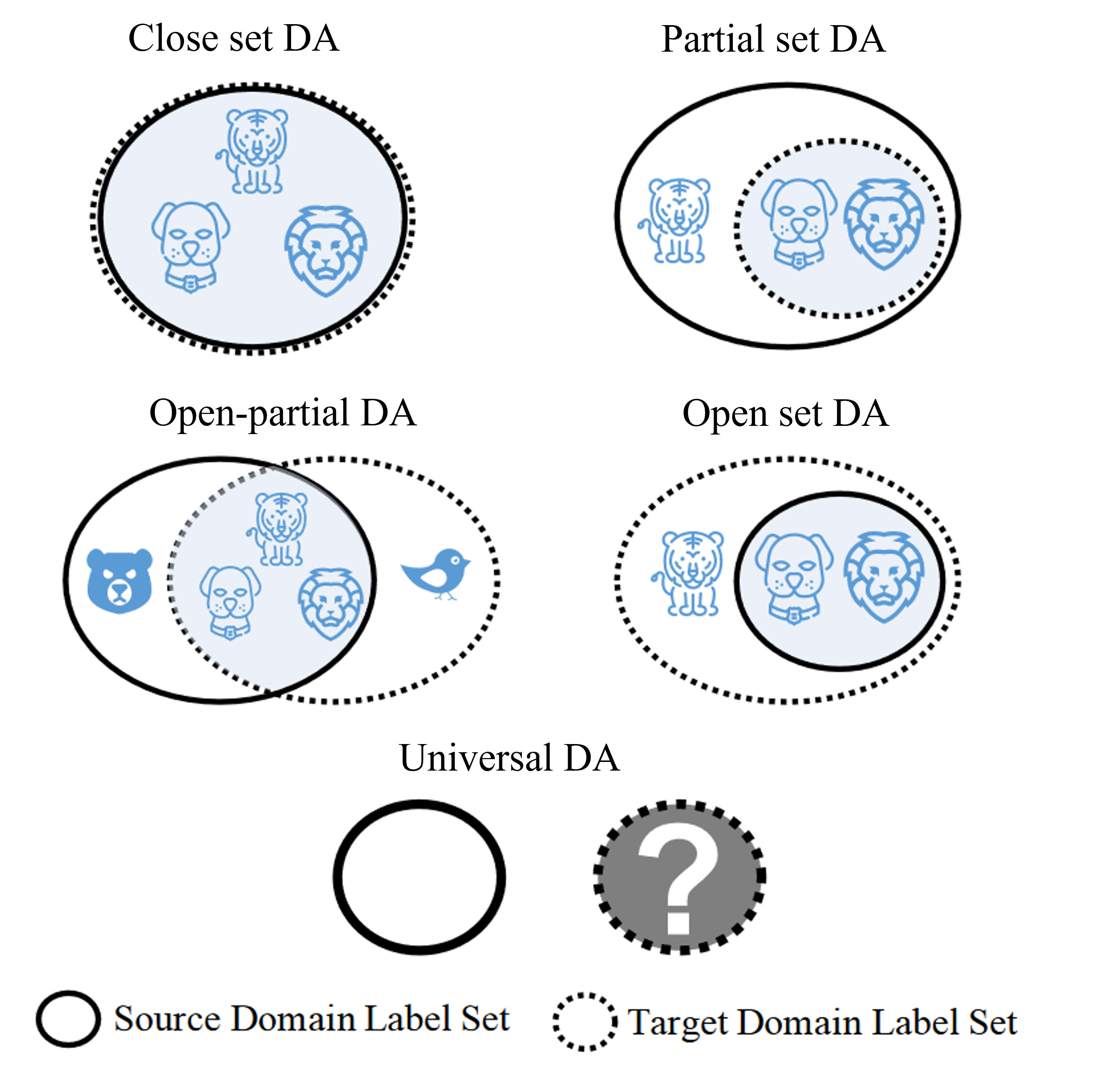
- closed set DA:源标签集和目标标签集相同
- partial DA:目标标签集是源标签集的子集
- open set DA:源标签集是目标标签集的子集
- open-partial DA:源和目标标签集中存在各自私有的标签集和共同的标签集
- universal DA(this essay):源标签域已知,目标标签域未知,对于任何目标域,如果属于源标签集中的任何类别,则对其进行正确分类,否则标记为unknown类
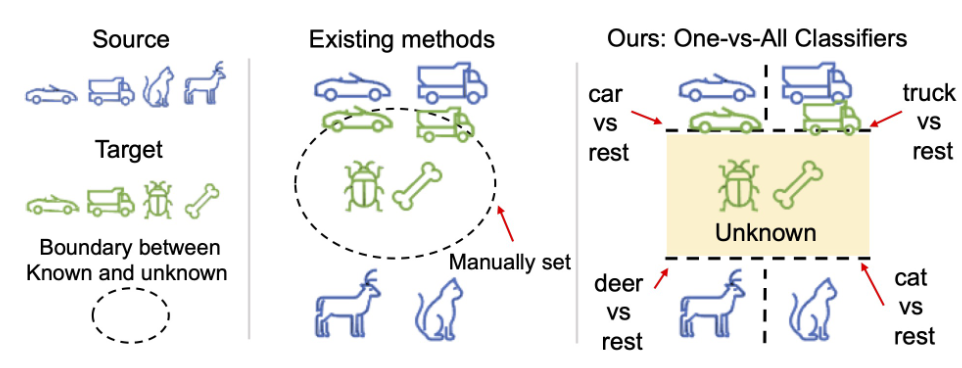
Current methods
目前的方法人工设定了一个阈值来拒绝unknown实例或通过先验知识进行验证。
- 拒绝一定比例的目标样本,此方法在拒绝比率准确的时候效果较好,但是在没有标记的目标样本情况下估计拒绝比率很难。
- 使用标记的目标样本验证阈值决定unknown:破坏了”没有标记的目标样本“的前提。
- 合成unknown实例:通过可学习模型定义unknown的概念,但是调整生成过程需要标记样本进行验证,否则生成的数据不一定与真实unknown数据相似。
需要实现一个方法既不需要人工设定拒绝阈值,也不需要标记的目标样本进行验证。
作者提出能否利用源类的类间距离来学习阈值,假设最小的类间距离是一个很好的阈值,用于确定样本是否属于该类别。即如果一个样本与一个类的距离小于边距,则属于该类;反之如果一个样本不属于任何类,则标记为unknown。因此作者提出为每个类训练one-vs-all的分类器,该分类器通过类间距离学习边界。如果所有类别的分类器认为某样本不属于他们,则该样本标记为unknown。
一些符号标记
- \(D _ { s } = \left\{ ( x _ { i } ^ { s } , y _ { i } ^ { s } ) \right\}\):源域,包含\(N _ {s}\)个标记的样本
- \(D _ { t } = \left\{ ( x _ { i } ^ { t } ) \right\}\):目标域,包含\(N _ {t}\)个未标记的样本
- \(L _ {s}\):源域的标签集
- \(L _ {t}\):目标域的标签集
- \(O\):one-vs-all open-set classifier,使用学习到的类间距离识别未知样本,通过标准分类损失来训练以对源样本进行分类,在测试阶段用于确定样本是否属于未知类
- \(C\):closed-set classifier,将样本分类到源标签\(L _ {s}\)中,通过HNCS训练,在测试阶段用于识别最近的已知类
Structure
OVANet主要分为两部分,第一部分是学习边界;第二部分是适应目标域。
train在源域和目标域的并集上,test在目标域上
两个分类器:
| 分类器 | one-vs-all open-set classifier | closed-set classifier |
|---|---|---|
| usage | 检测未知样本,标记为unknown | 将样本分类到源标签中 |
| train | ova loss | 交叉熵损失 |
| test | 确定样本是否属于未知类 | 识别最近的已知类 |
open-set classifier由\(L _ {s}\)个子分类器组成,每个子分类器用于区分样本是否属于该类别并输出一个二维向量,表示该样本属于该类的概率和不属于该类的概率。学习内点和离群点的边界
前人使用的one-vs-all是对于每个子分类器,训练其与\(L _ {s} - 1\)个类别的边界,但是当\(L _ {s}\)很大的时候这种方法并不有效,原因在于open-set classifier可以很容易地将许多negative类分类成positive类,也就是边界比实际的大很多。(比如猫狗龟,要为猫类学习边界应该更关注于与其相似的狗而不是乌龟,上述方法学习到的边界可能在猫和乌龟中间)因此作者提出hard negative sample的概念,为每个样本训练positive类和其nearest negative类的分类器。
Hard Negative Classifier Sampling (HNCS)
Hard Negative Class:different from the class but similar to it(nearest negative class)
每个类与其他类的类间距离最小值一定是与Hard Negative Class的类间距离,因此对于每个源样本,更新一个positive和一个hard negative的open-set分类器,以高效学习每个类的类间距离最小值也就是边界。
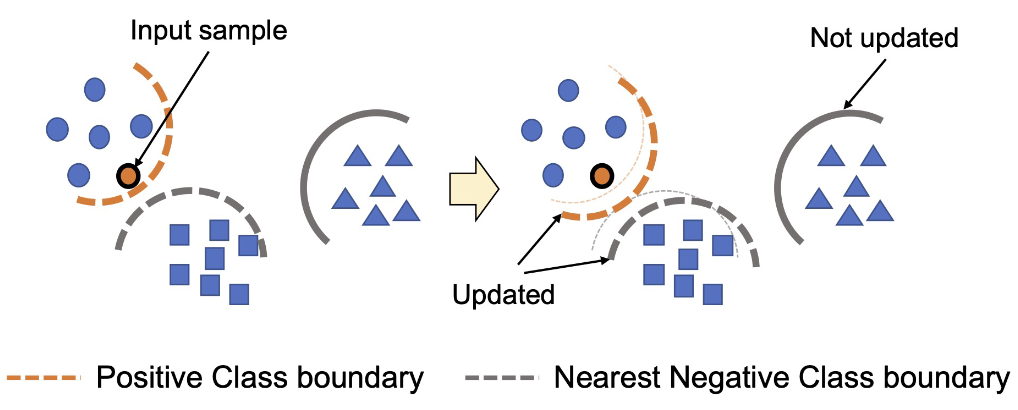
| 对于每个子分类器\(k\),首先提取特征\(z ^ { k } = w ^ { k } G _ { \theta } ( x ) \in R ^ { 2 }\),其中\(G _ { \theta }\)表示特征提取器,\(w ^ { k }\)表示分类器对于类别\(k\)的权重,\(z ^ { k }\)的两个维度分别表示known和unknown的得分。样本\(x\)属于类别\(k\)的概率表示为$$ p ( \widehat { y } ^ { k } | x ) = \sigma ( z ^ { k } ) _ { 0 }\(,其中\)\sigma$$为激活函数。 |

Open-set Entropy Minimization (OEM)
因为open-set classifier是在源域上训练的,作者建议增强未标记目标域中低密度分离。由于目标样本与源样本具有不同的特征,因此无论使用什么分类器,目标样本都可能被错误分类。为此提出了一种新颖的熵最小化方法使open-set classifier适应目标域。
具体来说:对每个未标记的目标样本的所有开放集分类器应用熵最小化训练,计算所有分类器的熵并取平均值,并训练一个模型来最小化熵。
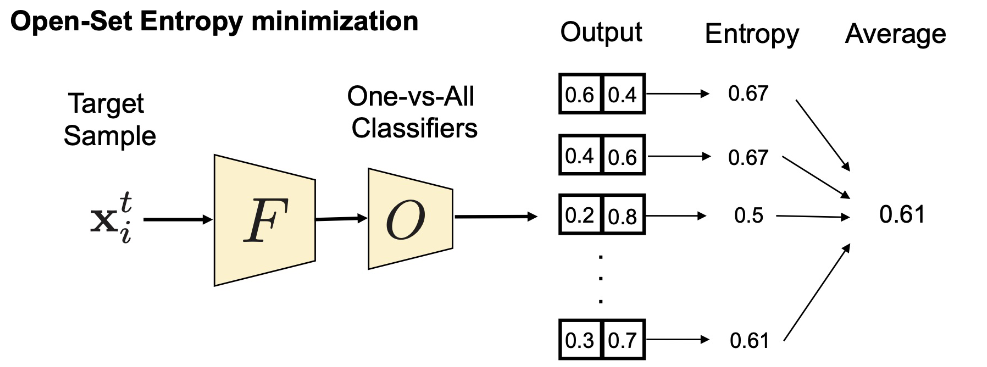
通过这种熵最小化,已知的目标样本可以与源样本对齐,而未知的样本可以保持未知。与现有的熵最小化方法[12]的一个明显区别是,由于熵最小化是由开放集分类器而不是封闭集分类器来执行的,我们可以将未知实例保留在未知状态。封闭集分类器进行的熵最小化必然会使未标记的样本与已知类对齐,因为没有未知类的概念。由于我们的开放集分类器具有未知概念,模型可以增加其置信度。
Loss Function
结合开放集分类器和封闭集分类器来学习开放集分类和封闭集分类。
对于closed-set分类器:在特征提取后训练一个线性分类器,使用交叉熵损失,表示为\(L _ { c l s } ( x , y )\)。
-
cls表示closed-set分类器的交叉熵损失
-
ova表示open-set分类器的损失
最大化样本属于正确类别的概率和样本属于其最接近负类的概率
- ent表示熵最小化的损失
总损失函数如下:
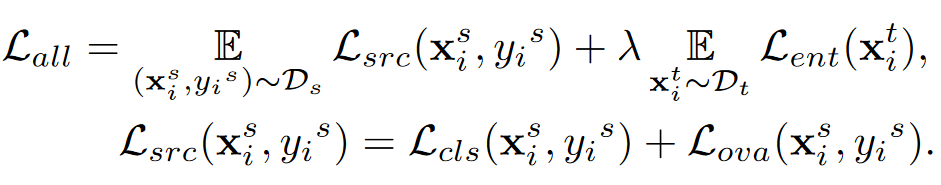
其中只有一个超参数\(\lambda\)。
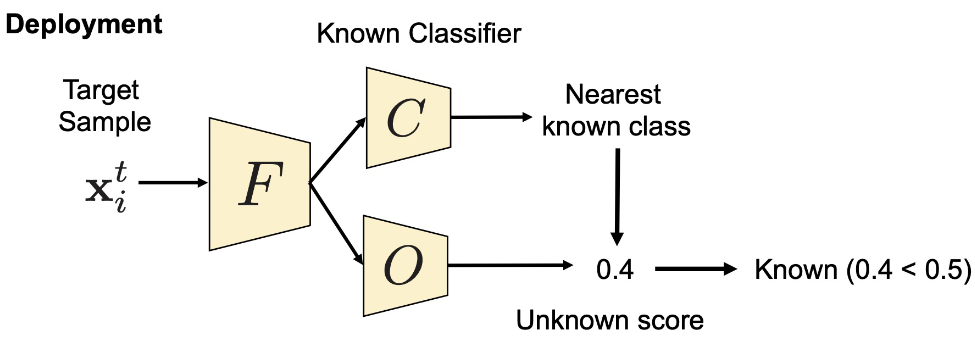
在测试阶段,首先通过closed-set分类器获得最接近的已知类(Hard Negative Class),然后采用open-set分类器的相应分数。
Experiment
Dataset
使用数据集:Office, OfficeHome, VisDA, DomainNet
将数据集拆分为:shared, source-private, target-private种类,表示如下 \(| L _ { s } \cap L _ { t } | / | L _ { s } - L _ { t } | / | L _ { t } - L _ { s } |\)
Evaluation Metric
H分数:是已知类\(acc _ {c}\)和未知类\(acc _ {t}\)的准确性调和平均值,当两个准确性都很高的时候H分数才会高,因此它可以很好地衡量universal DA方法的准确性。 \(H _ { s c o r e } = \frac { 2 a c c _ { c } \cdot a c c _ { t } } { a c c _ { c } + a c c _ { t } . }\) 缺点在于已知类和未知类的权重永远相同,当未知实例数量较小时,该度量会过度强调未知类别。因此在数量较少的时候,作者将所有样本的实例精度也展示了出来。
Implementation
骨干网络backbone:在ImageNet上预训练的ResNet50
Evaluation:VGGNet
\[\lambda = 0.1\]Baselines
旨在与可以拒绝未知样本的UDA方法进行比较。
Results
在Office数据集上,将已知类别固定为10,未知类别从2到20改变,结果显示OVA优于其他的方法。
在OfficeHome上选择了五个适应场景覆盖不同的域,改变未知类为5、10、15,得到的结果与Office上类似。
还计算了在OfficeHome中12个适应场景的均值;在VisDA中,类别数目较少,OVA的得分比其他方法高出10分以上;在DomainNet中,类别数目较多,平均效果优于其他方法。
在所有不同的设置中都优于或与基准方法相当,而无需为每个设置优化超参数。
Ablation
acc close:衡量识别已知样本的准确性,而不拒绝任何未知样本(评估封闭集识别的能力)
UNK:衡量拒绝未知样本的准确性
AUROC:衡量在给定open-set分类器输出,已知和未知样本的分离效果,区分已知样本和未知样本的能力。
结果如下图,可以看出OEM对提高拒绝未知样本的准确性方面效果突出,对于提高封闭集识别准确性也有效;而HNCS对各方面均有提升,在DomainNet数据集上效果最明显,原因在于该数据集中已知类非常多,可以有更多的negative类来训练分类器。

Analysis
-
该模型能够很好地分离已知样本和未知样本
- OEM对超参数不敏感
-
提高source-private类别的数量,由于有更多的异常源类,正确分类目标类可能变困难,因此效果会有所下降,但是相比于熵分类方法,OVANet相对稳定很多。
-
固定未知类别数量,增加已知类别数量时,封闭集的准确性略有降低,拒绝未知类别的准确性提高或保持不变,模型更有可能为已知类别学习到好的边界。
-
OVA中open-set分类器和closed-set分类器缺一不可,如果只用open-set分类器,该分类器的训练目标只考虑将一个已知类别与其他类别区分开,而不是区分已知类别。
- OVA网络在半监督学习中也有效
Conclusion
我认为本文的最重要的工作是设置了hard negative class使得分类器的工作量大幅减小并且效果变好;其次在开放集中应用熵最小化可以合理处理目标样本被标记为已知样本的问题。