
Masked Autoencoders Are Scalable Vision Learners
CVPR 2022
Abstract
提出MAE,具体来说随机盖住输入图片里的一些patch然后重建这些像素,设计了一个非对称的编码器解码器架构,编码器只对没有覆盖的patch进行操作,解码器用来重建被覆盖的像素。当覆盖很大一部分输入图片时,模型可以被迫学习到更多有用的信息(当覆盖很小一部分图片时通过插值即可得到原图像),因此MAE结合上述两部分可以在计算机视觉领域高效训练大模型。
Architecture
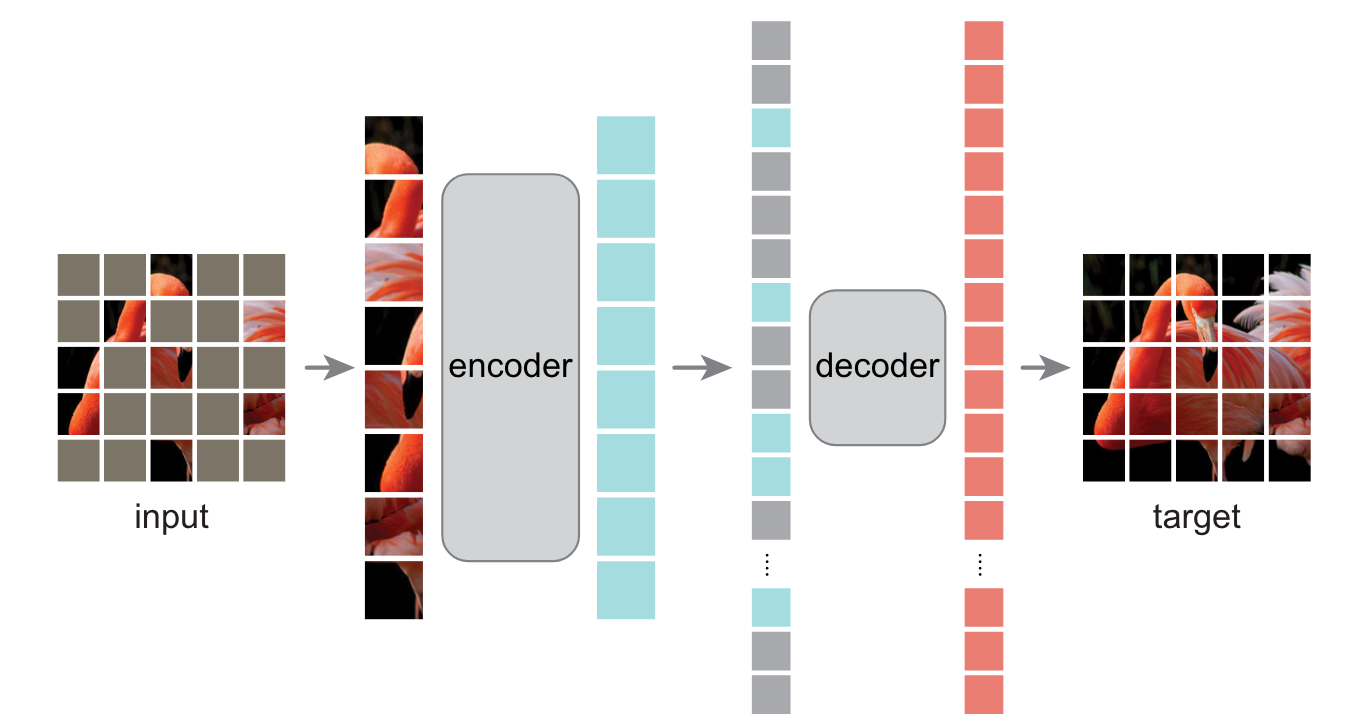
mask:与ViT相同,首先将图片划分为许多不重叠的patch,随后随机采样一部分patch(一小部分)并将其余patch盖住。
encoder:与ViT的encoder架构相同,不同的是只对那些没有被盖住的patch进行编码
decoder:可以看到被盖住的patch和已经被编码的没有被盖住的patch,架构由一系列的transformer block组成,只用在预训练过程。
Experiment
- ImageNet-1K:首先在该数据集上做自监督的预训练(mask),然后做有监督的微调(分类)。
- 进行了一些消融实验以及一些模型效果的展示
- 与其他模型在不同数据集上效果进行对比
- fine- tuning不同数目的层的精度对比
- 迁移学习:进行了目标检测,语义分割等任务并展示了模型效果
Others
- 可以说是BERT运用到CV领域的一个工作
- 标题:什么是一个好东西
- 在做下游任务时候只需要encoder,不需要decoder,也不需要对输入图片进行mask。
- intro写法:问问题,回答问题,提出自己的思路
- related work:没有写出与MAE最相关工作的不同,比如BEiT,iGPT等。建议在写论文的时候在该部分写出与此篇论文最相关的工作以及与这些工作的区别在哪。
- 实验部分十分详细,工作内容很多
- 微调的时候如果只调最后一层会比较快但是模型精度通常较差;如果每一层都调会比较慢,模型精度通常较好
- 盖住更多的patch使得未被盖住的patch之间冗余度较低,使得任务变得更复杂
- 使用transformer架构的解码器直接还原原始像素信息,使得整体流程简单
- 加上在ViT工作之后的各种技术使其更加鲁棒