
A Survey on Knowledge-Enhanced Pre-trained Language Models
Abstract
自然语言处理(NLP)已经通过使用BERT等预训练语言模型(PLM)发生了革命性的变化,但还面临许多挑战包括较差的可解释性、较弱的推理能力,以及在应用于下游任务时需要大量昂贵的注释数据。通过将外部知识集成到PLM中,知识增强预训练语言模型(KEPLM)具有克服上述限制的潜力。本文概述了KEPLMs中常见的知识类型和不同的知识格式,详细介绍了现有的构建和评估KEPLMs的方法,介绍了KEPLMs在下游任务中的应用并讨论了未来的研究方向。
Introduction
早期的PLMs是浅层神经网络并且词嵌入是静态语义向量,这使得其不能解决不同场景下一词多义的问题。随着深度学习的发展以及自监督学习的出现,大语言模型可以通过预测预先被掩盖的标记,从大规模未标记的文本数据中学习到大量知识,从而在许多下游任务中取得突破并且PLMs开始快速发展。
随着研究的推进,研究者发现PLMs也有上述的一些问题,并且PLMs不够健壮因为深度神经模型易受对抗样本的影响。所有的这些缺点都可以被改善通过合并外部知识,这也就造就了KEPLMs。
Background
本文主要研究通过知识增强PLMs,在很多知识增强的下游任务中,通过添加参数,可以增加PLMs学习到的知识量但这远不如直接整合知识有效,因此将知识融合到PLMs中很有必要。
Knowledge Sources For KEPLMs
Types of Knowledge
语言知识:
1.词性标记:包括名词、动词、形容词、副词、代词等
2.语法结构:包括成分语法分析和依存语法分析。Syntax-BERT使用与语法相关的掩码来合并来自选区和依赖树的信息。K-Adapter集成了依赖解析信息,提高了依赖关系预测任务的性能。
3.跨语言可转移性:有时候通过学习多语言语料库,PLMs可以获得跨语言可转移性,也就是一种语言的语言知识可能有助于处理另一种语言。
语义知识
旨在帮助模型捕捉文本的含义。融入语义知识的模型在机器阅读理解、词义消歧、词汇简化等方面表现更好。
常识知识
常识知识是人们对日常世界和活动的常规知识
表示成三元组,和百科知识不同的是头和尾实体通常是短语而不是单词
eg:
常识知识三元组:having no food, CauseDesire, go to a store
百科知识三元组:China, capital, Beijing
百科知识
百科知识涵盖了开放领域的广泛信息,以文本或三元组的形式。维基百科是一个多语言的非结构化百科全书。BERT利用它作为预训练数据集学习上下文表示。
维基数据是整合百科知识时使用最广泛的知识图谱。许多KEPLMs使用它作为知识源。其他常用的英语百科知识图谱包括Freebase、DBpedia和NELL。CN-DBpedia是一个广泛使用的中文百科知识图谱。
领域知识
与百科全书式的知识相比,领域知识是特定的、专门领域的知识
比如生物医学知识通常表示成包含症状或疾病作为头或尾实体的三元组
eg:细菌性肺炎,伴有相关形态学、炎症
Formats of Knowledge
实体词典
为了通过实体整合知识,我们需要将实体的知识嵌入集成到对齐的token嵌入中。
现有模型提出了两种获取初始实体嵌入的方法,一种是通过传统的知识嵌入算法获得初始实体嵌入,另一种是通过对实体描述进行编码。第一种方法可以融合知识库中实体相邻节点的信息。但由于文本中的词与KG中的实体的嵌入向量空间不一致,必须面对异构嵌入空间的挑战。第二种方法是在同一嵌入空间中融合信息,但实体嵌入可能不能完全表达实体的含义。
知识图谱
1.三元组:
存储在知识图谱中的知识通常以语义三元组的形式,为了合并三元组,我们可以将三元组附加到文本中的适当位置,或者将它们的嵌入集成到文本嵌入中。
2.子图:
知识子图是以实体为节点,以关系为边的知识图的一部分。
纯文本
为了整合文本中的知识,我们可以将知识三元组转换为句子作为预训练语料库,或者在文本中添加相关的实体定义。这种方法适用于常识性知识库,因为常识性知识库中的三元组通常是短语,只需要添加连词即可获得句子。
标题图片
为了整合视觉知识,模型可以首先检索与上下文相关的图像,对其进行编码,然后将图像的嵌入整合到文本嵌入中。视觉知识也可以通过文本-图像对齐预训练目标进行整合。
Building KEPLMs
Implicit Incorporation of Knowledge
知识引导掩蔽策略
PLMs通常使用非结构化的文本数据作为预训练数据集,PLMs可以通过Masked Language Modelling(MLM)从非结构化的文本数据中学习到丰富的上下文语义信息,但是会忽略同样包含重要信息的实体和短语。通过采用超越单个单词水平的知识引导掩蔽策略,PLMs能够整合关于实体和短语的知识。
ERNIE:添加实体级和短语级的掩蔽策略,指导BERT的预训练融合文本中的实体和短语信息
SKEP:不掩盖实体和短语,而是掩盖情感词,从而将情感知识注入文本表示
GLM:使用知识图谱知情采样,为更重要的实体分配更高的权重。具体来说,GLM的屏蔽策略会在20%的时间里屏蔽一个普通单词,在80%的时间里屏蔽一个实体。当GLM需要屏蔽一个实体时,那些能够在ConceptNet中特定跳数内到达句子中其他实体的实体被认为是更关键的,并被赋予更高的选择概率(权重)。因此GLM可以将keplm的构建推向知识图中更关键的实体。
eg:假设句子中有四个实体,其中三个实体在一定跳数内可以互相到达,但是sometimes不能,所以GLM将会给前者更高的概率比起后者
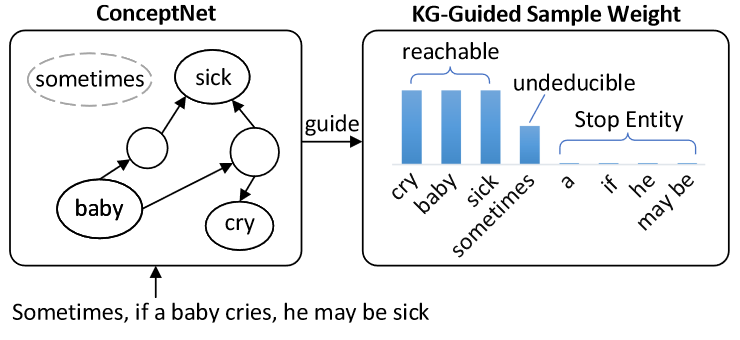
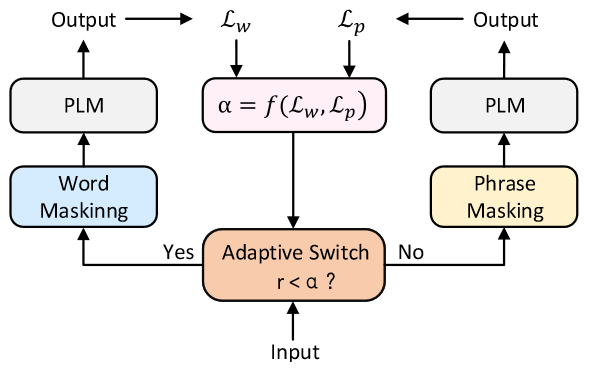
E-BERT:提出了一种自适应混合掩蔽策略,该策略允许模型在预训练期间以自适应的方式在词级和短语级掩蔽之间切换。
eg:r是每次迭代中随机生成的数,损失函数Lw和Lp来跟踪学习到的词级信息和短语级信息的拟合进度,词级掩蔽相对于短语级掩蔽的相对重要性rt进一步用于计算αt+1使得当前迭代中损耗较大的模态更有可能在下一次迭代中被选择。
知识相关的预训练任务
一些构建keplm的方法通过添加与知识相关的预训练任务来隐含地整合知识(fig6)
KALM:用实体信号丰富输入序列,然后在预训练目标中加入实体预测任务
KEPLER:增加了知识嵌入预训练任务,该任务与MLM共享一个Transformer Encoder,同时获得文本增强的知识嵌入和知识增强的预训练语言模型
Explicit Incorporation of Knowledge
PLM显式知识整合的方式主要有三种:修改模型输入、增加知识融合模块和利用外部存储器。前两种方法以额外输入或者额外的组件的形式将相关知识插入到模型中。第三种方法使文本和知识空间保持独立,便于知识更新。
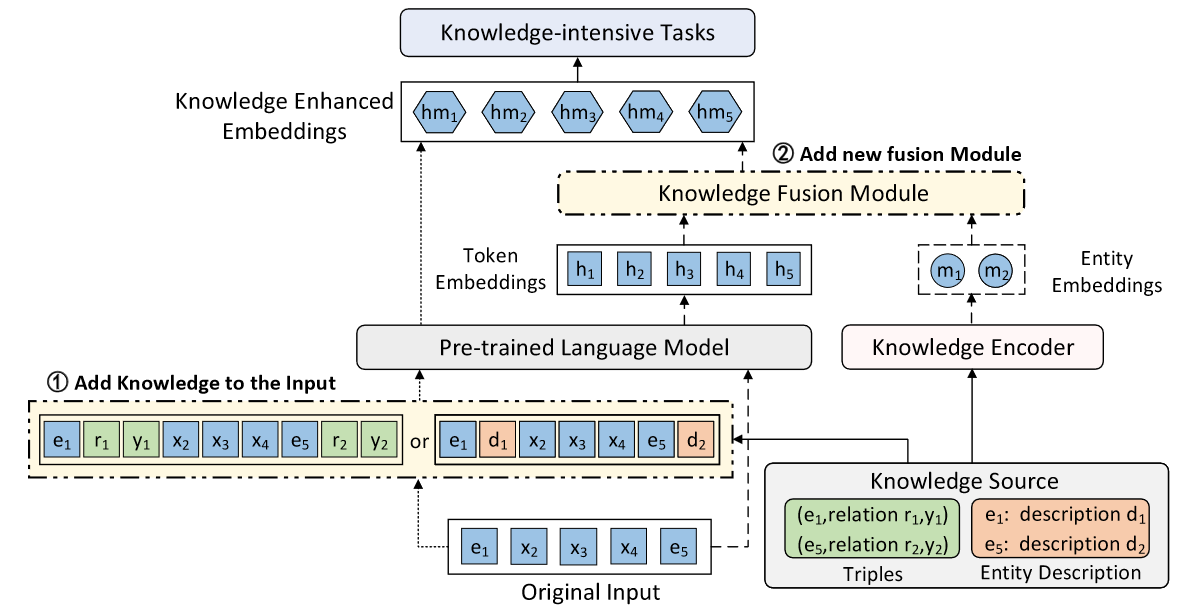
修改模型输入
一些KEPLMs在预训练过程中将相关的知识三元组或实体描述插入模型的输入中。
1.以三元组的形式合并知识有几种不同的方法:
ERNIE:在句子前添加相关三元组作为扩展的模型输入。
K-BERT:在每个句子中注入相关三元组,生成一个句子树用于模型输入。具体来说,如果输入的句子中有一个实体“apple”,K-BERT将会在知识图谱中寻找以“apple”为头实体的句子然后将这些三元组中的关系和尾实体加入并生成一个新的句子树。
CoLAKE:将文本作为一个全连通词图,整合知识形成词-知识图谱。
2.以实体的形式合并知识也有几种不同的方法:
Dict-BERT:从维基词典中获取句子中生僻词的定义,并将其附加到句子的末尾。
DKPLM:关注于长尾实体,并使用来自相关三元组的伪令牌表示来替换它们的嵌入。
WKLM:用相同类型的其他实体代替文本中的实体,然后将其输入模型并要求模型确定句子中哪些实体是正确的,哪些实体是替换的,该方法没有修改模型,只是修改了预训练过程中的输入数据。
3.下面详细介绍两个表现比较好的模型使用的方法:
CoLAKE:
将每个输入句子视为一个全连通图。它以输入句子中的实体作为锚节点,并引入一个子图(由以该锚节点为知识图谱中的头实体的三元构成)来获得词知识图谱。然后将词知识图谱中新增的节点附加到原始输入文本后面,并一起输入到PLM中进行预训练。CoLAKE在新获得的输入语句中区分节点类型,并对不同的节点进行不同的初始化。这些节点包括词节点、实体节点和关系节点。
DKPLM:
提出了长尾实体的概念,表示模型从语料库中未完全学习到的实体。在预训练阶段加强这种长尾实体的学习,可以增强模型对语义上下文的理解,最终增强语言表示。
为此,提出了一种KLT度量方法来识别长尾实体:将每句话中KLT得分低于平均值的实体视为该句话的长尾实体。
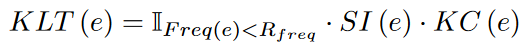
公式中e表示实体,Freq(e)表示实体在语料库中出现的频率,SI(e)表示语义重要性,KC(e)表示在KG中实体e特定跳数的邻居节点数量。
DKPLM将文本中检测到的长尾实体嵌入替换为伪标记嵌入,作为模型的新输入。
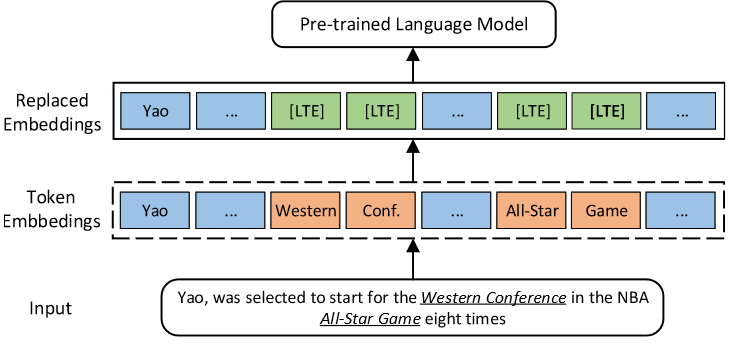
eg:
在输入句子中“Western Conference” 和 “All-Star Game”被检测为长尾实体,所以它们的嵌入将被替换为伪令牌嵌入即[LTE]。DKPLM在实体分类和关系分类上的F1得分分别比RoBERTa高2.1%和2.87%,证实了将长尾实体知识纳入plm可以获得更好的语言表示和更高的模型性能。
F1分数:统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。
增加知识融合模块
本节介绍的方法都涉及不同模态空间的融合。具体来说,文本和知识模态的编码是不同的,并构建了额外的模态融合模块,这种知识融合模块主要出现在三个位置:
a.在整个PLM的顶端
b.在PLM的Transformer层之间
c.在PLM的Transformer层内部
(a)部分可以进一步分为两种类型
一种是T-K结构。主要以实体嵌入的形式对知识进行整合:T-Encoder后是K-Encoder,其中T-Encoder对文本语料库进行编码,K-Encoder将知识空间中的实体嵌入整合到文本空间中的实体嵌入中。许多KEPLM遵循这种结构,但在如何获得实体嵌入方面有所不同。
ERNIE中的实体嵌入是通过TransE获得的,TransE以单个三元组作为训练样本,不包含该实体相邻节点的信息。
以此为基础,BERT-MK在学习知识空间中的实体嵌入时充分考虑了相邻节点的信息,融入了更多的语义信息。
上述方法不能根据上下文信息动态变化,因此为了克服这一限制,相邻节点的含义与文本越接近,CokeBERT将更多的信息纳入实体嵌入中。
另一种是在PLM之后附加其他知识融合结构。一些keplm使用注意机制来融合文本信息和知识模式。Kwon等人利用注意机制将句子相关三元组纳入文本嵌入表示;JointLK允许每个问题令牌参与KG节点,每个KG节点参与问题令牌,两种模态表示通过多步交互相互融合和更新;KET采用分层自关注机制,将情感知识整合到文本表示中;Liu等人对上下文中的相关三元组进行编码,然后使用门机制将它们与文本的嵌入融合在一起。
还有其他基于交互节点的工作。这两种模式都通过交互节点交换信息。QA-GNN 通过交互节点将文本空间中的信息整合到知识空间中,在常识性问答中取得了较好的效果。受此启发,GreaseLM在两种模态中设置交互节点,分别学习该模态的知识,然后在融合层交换信息,学习另一模态的知识。
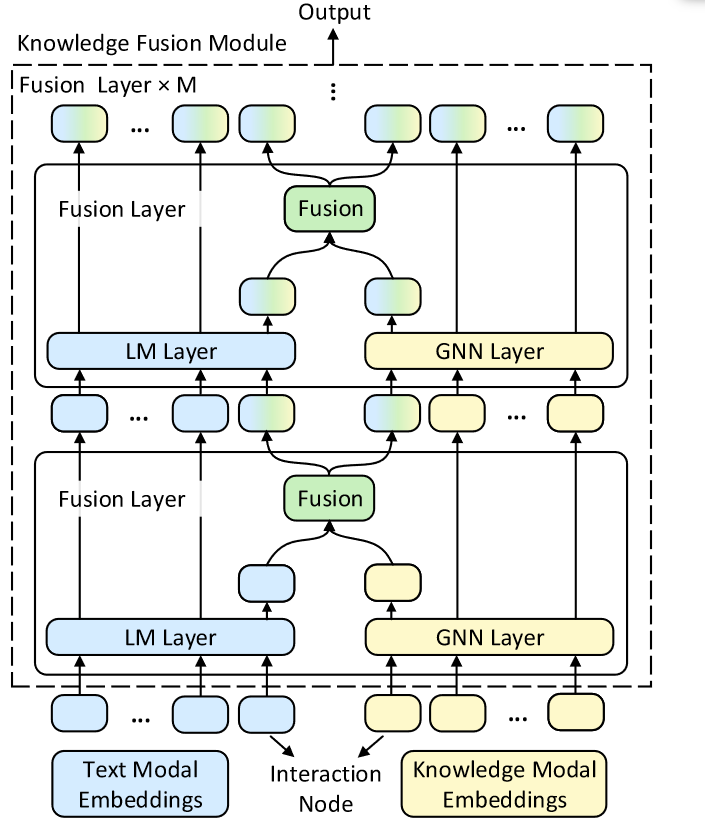
(b)中的方法是在PLM的Transformer层之间增加知识融合模块。
KnowBERT:在Transformer Encoder块之间添加了新的模块,以将有关实体的知识整合到句子中。同时考虑到了一词多义问题,对于一个在不同语境中表现出不同语义的实体,根据其特定的意义来整合关于它的知识。
KGBERT:在编码器和解码器层之间增加了知识融合模块,通过多头图注意机制将知识子图中的信息集成到文本表示中
JAKET:JAKET将预训练的语言模型分为前六层和后六层。文本经过编码器的前六层后,就得到了隐藏层和实体嵌入的表示。在文本中的每个实体位置,添加相应的实体嵌入表示,然后输入到模型的最后六层进行后续训练。知识空间和文本空间可以相互循环强化,以学习更好的模型。
(c)中的方法是在PLM的Transformer层内部增加知识融合模型。KALA将知识融合模块插入Transformer块层中。以这种方式添加知识融合模块直观,合并的知识以实体表示为主。有些方法考虑了知识图谱中实体的上下文;其他一些基于文本上下文过滤实体邻居节点以进行嵌入。
利用外部存储器
构建KEPLM的第三种方法显式地使用外部内存,从而保持知识空间和文本空间的分离。
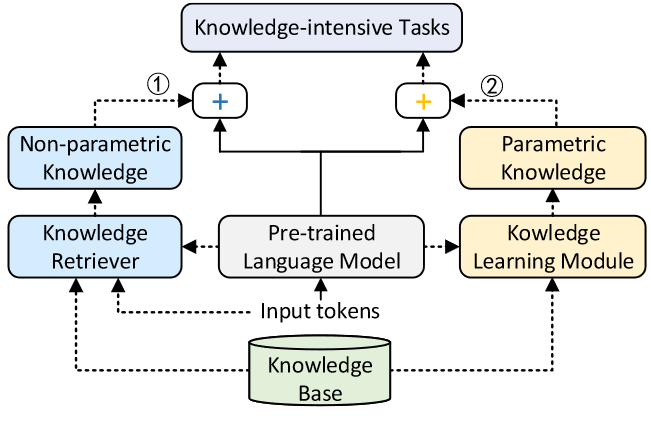
在图1中说明了将外部存储器中的非参数知识应用于下游NLP任务的方法。
KGLM:从相关的知识图中选择并复制事实来生成句子。换句话说,它使用知识库来扩展词汇表,以提供它以前从未见过的信息。
REALM:引入了知识检索器,帮助模型从知识语料库中检索和处理文档,从而提高了开放域问答的性能。
在图2说明了使用独立于PLM的附加模块学习参数化知识的方法。
K-Adapter:加入适配器学习参数化知识,预训练时PLM本身参数保持不变。这些适配器彼此独立,可以并行训练。
当知识库发生了一些变化时,将知识保存在外部存储器中有一个很大的优势,即KEPLM不需要重新训练,这对于知识经常更新的应用程序领域特别有帮助。