
Hybrid neural networks for on-device directional hearing
AAAI 2022
有待补充的blog
Abstract
结合了传统波束成形(减轻计算负担,提高泛化性)和自定义的轻量级神经网络(减小内存和计算开销,实现实时和低延迟操作)。
传统波束成形:计算上轻量级但是性能有限
神经网络:性能好但是计算昂贵,不能运行在可穿戴计算平台
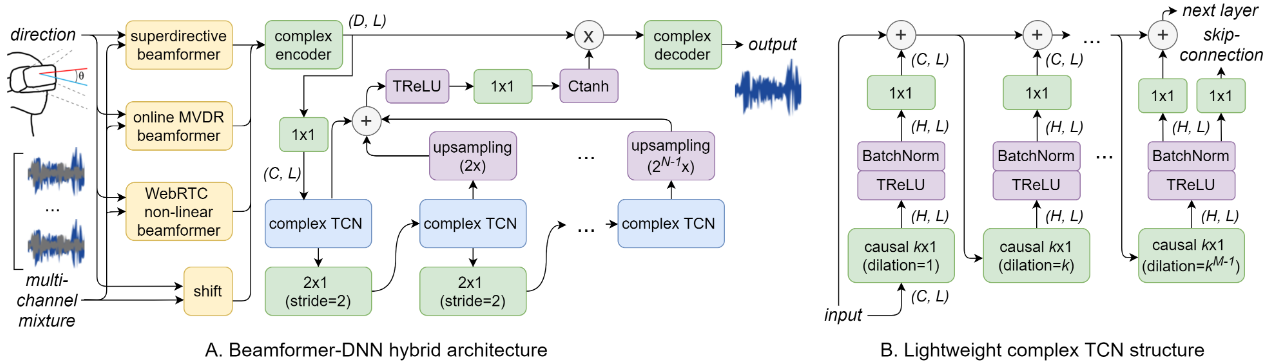
Architecture
输入信号首先通过三个不同的轻量级beamformer处理,产生三个不同版本的beamformered signal,这三个信号和原始信号一同被输入到神经网络中。
Prebeamforming
三种统计波束形成器从非自适应、自适应和非线性方法跨越了不同类型的波束形成技术。因此为后续神经网络的输入信息提供多样的空间信息。
- superdirective beamformer:在扩散噪声下进行优化
- online adaptive MVDR beamformer:提取空间信息,抑制噪声和干扰
- WebRTC non-linear beamformer:抑制更可能是噪声或干扰的时频成分
此外对输入channel转变到输入direction上(没看懂)
Neural Network
Complex Tensor Representation
使用复张量可以在准确性不下降的情况下有效减小模型大小,每个参数可以表示为\([R, -I, I, R]\)而不是一个\(2 \times 2\)矩阵。同时复神经网络在无线沟通,噪声压缩等方面更有效。
ps:复数乘法捕获复数域中的旋转,可以很容易地操纵信号的相位。
缺点是全复数神经网络对于共轭操作和相位缩放的效率低,因此引入一个额外的component-wise operation,定义\(TRELU(x _ {c, t})\)如下:
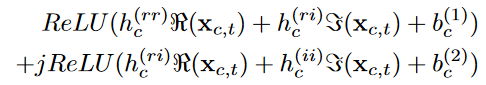
其中x为复数输入、c为channel、t为time indices、h和b是训练得到的参数。
该操作对既能模拟共轭缩放又能模拟相位缩放的2D复空间进行线性变换,然后分别对实部和虚部独立进行relu激活操作。
Complex Masking
分离器输出一个从0到1的复掩码范围,与编码器输出相乘后送入解码器。当掩码不能超过1时,可训练的编码器和解码器可以缓解这一限制。我们在保留角度分量的同时对复张量的幅值进行tanh运算。 \(C \tan h ( x ) = \tan h ( | | x | | ) \ast \frac { x } { | | x | | }\)
Strided Dilated Convolution
由N个TCN(时序卷积网络)堆叠而成。在每个包含M个空洞卷积层的TCN之间,我们添加了一个步长为2的2 × 1卷积层对信号进行下采样,有效地减少了后续层的填充大小。在求和之前,根据原始采样率,使用最近邻方法对跳跃连接进行上采样。
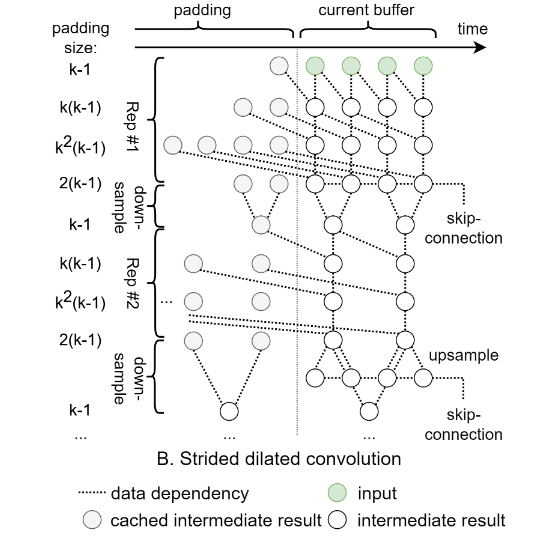
简化版TCN:
- 使用传统卷积而不是D-conv(depthwise separable convolution)
- 对每个TCN stack只在最后一个卷积层上应用skip-connections
- 我们将膨胀增长因子k放宽到2以上
Evaluation
我们还合成了另一个版本,其中只有一个声源和第一个麦克风存在,并且没有产生混响作为groundtruth
Limitations
- 更大的真实世界数据集
- 双耳设置?
- CPU的替代品:DNN、GPU等
- 更低的延迟?
- 运行时间优化:网络剪枝和量化