
Generative Adversarial Nets
NIPS2014
Abstract
提出了一个新的framework用来通过对抗过程估计生成模型,在此框架中训练两个模型分别是生成模型G和辨别模型D。
- 生成模型G:用来抓取整个数据的分布(生成模型就是要对整个数据的分布进行建模,使得能够生成各种分布,这里的分布就是指的生成图片、文字或者电影等,在统计学中,整个世界是通过采样不同的分布来得到的,所以如果想要生成东西,就应该抓取整个数据的分布)
- 辨别模型D:用来估计样本到底是从真正的数据生成出来的还是来自生成模型G生成出来的
G的训练过程是使D出错的概率最大化(生成模型一般是尽量使数据分布接近,但是这个地方有所不同,它是想让辨别模型犯错)。在任何函数空间的G和D中存在一个独一无二的解( G 能够恢复真实训练数据分布,D对于任何样本都等于1/2)。如果G,D是MLP的话则可以通过反向传播训练,不需要任何的马尔科夫链或着说对一个近似的推理过程展开,简洁同时模型效果很好。
Artrcture
训练两个模型:生成模型G和辨别模型D,目标函数如下
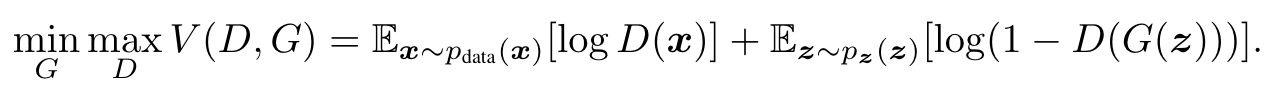
V(D,G)是一个价值函数,公式右侧是两个期望,其中x采样于真实分布,z是随机噪音。在D是完美的情况下,\(logD(x) = 0, D(G(z)) = 0\),因此公式右边均为0,如果D不完美,\(logD(x) < 0, D(G(z)) > 0\),则公式右边均小于0,因此我们需要最大化D的值。而G是希望辨别器尽量的犯错,因此我们需要最小化G(固定D,选择G,使V最小)。D是尽量把数据分开,G是尽量使生成数据分不开。如果达到了一个均衡,就是D不能往前进步,G也不能往前进步了,就认为达到了均衡,这个均衡叫做纳什均衡。
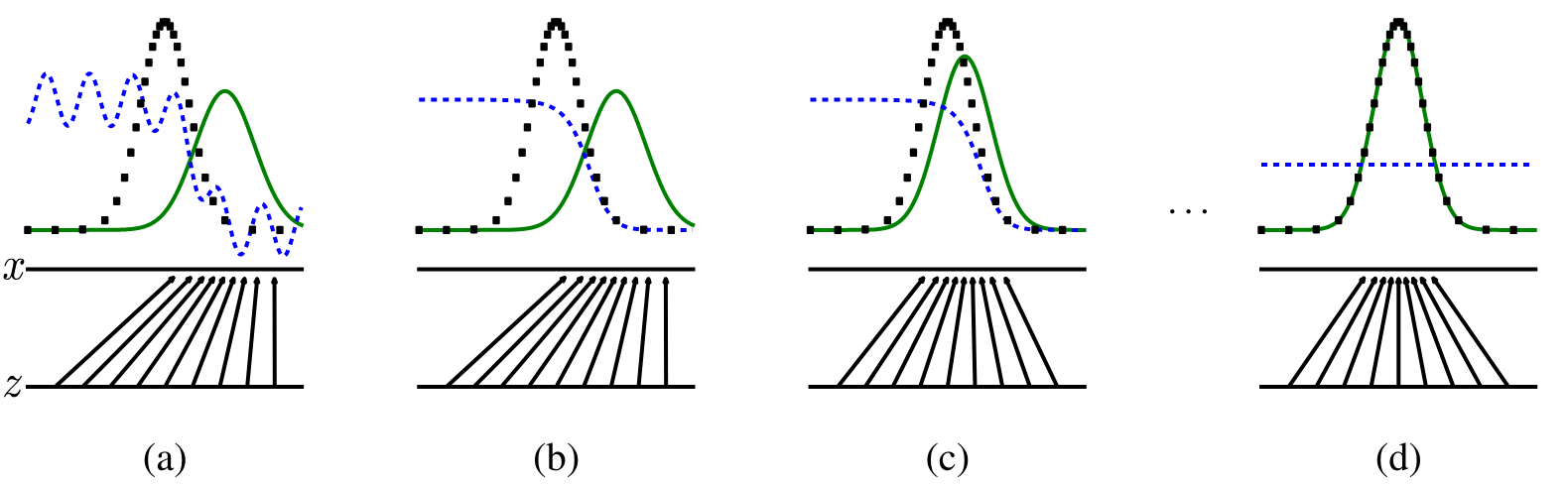
(a)表示第一步的时候,生成器将均匀分布进行映射,图中绿色的线就是把z映射成了一个高斯分布,此时辨别器视图中蓝色的线,表现一般
(b)表示更新辨别器,尽量把这两个东西分开,两个高斯分布的最高点表示真实分布和噪声最有可能出现的地方,辨别器需要在真实分布的地方值为1,在噪音分布的地方值为0,这样就可以尽量将来自真实分布的x和来自于生成器的x尽量分别开来
(c)表示更新生成器,使得能够尽量糊弄到辨别器(就是将生成器生成的高斯分布的峰值尽量左移,向真实数据的高斯分布进行靠拢),让辨别器犯错,这时候辨别器就需要尽量调整来把这两个细微的区别区别开来
(d)表示通过不断地调整生成器和辨别器,直到最后生成器的模型能够将来自均匀分布的随即噪音z映射成几乎跟真实分布差不多融合的高斯分布,即从真实的黑点中采样还是从生成器的绿线采样,辨别模型都是分辨不出来的(不管来自于哪个分布,辨别器对这每个值的输出都是0.5,这就是GAN最后想要的结果:生成器生成的数据和真实数据在分布上是完全分别不出来的,辨别器最后对此无能为力)
具体算法如下:

先更新辨别器再更新生成器,k是一个超参数,使得D的更新和G的更新在进度上差不多。
Theoretical Results
-
当G是固定的,即生成器是固定的情况下,最优判别器的计算如下
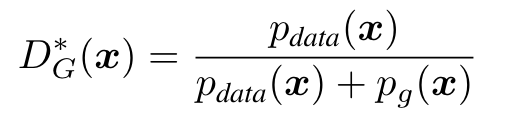
*表示最优解,\(p_{data}\)表示将x放进去之后在真实产生数据的分布中概率是多少,\(p_g\)表示将x放进去之后生成器拟合的分布概率是多少。当\(p_{data}\)和\(p_g\)完全相等的情况下值为1/2,也就是两个分布是完全分不开的。
-
当且仅当生成器的分布和真实数据的分布是相等的情况下,C(G)取得全局最小值
-
当G和D有足够的容量的时候而且算法一允许在中间的每一步D是可以达到它的最优解的时候,如果对G的优化是去迭代下图所示的步骤(式中G已经换成最优解了),那么最后的\(p_g\)会收敛到\(P_{data}\)。
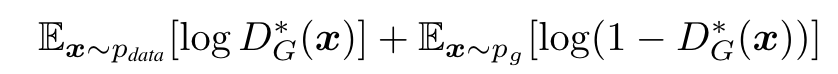
Others
- 整体来说,GAN的收敛是非常不稳定的,之后有很多工作对其进行改进
- 在算法的公式右边的第二项存在一定的问题,
- 在早期的时候G比较弱,生成的数据跟真实的数据差得比较远,这就很容易将D训练的特别好(D能够完美地区分开生成的数据和真实的数据),就导致log(1-D(G(z)))会变成0,它变成0的话,对他求梯度再更新G的时候,就会发现求不动了。所以在这种情况下建议在更新G的时候将目标函数改成最大化log(D(G(z)))就跟第一项差不多了,这样的话就算D能够把两个东西区分开来,但是因为是最大化的话,问题还是不大的,但是这也会带来另外一个问题,如果D(G(z))等于零的话,log(D(G(z)))是负无穷大,也会带来数值上的问题,在之后的工作中会对其进行改进
- two sample test:判断两个数据是不是来自同一个分布
- 如何快速判定训练集和测试集是否来自同一个分布:训练一个二分类的分类器进行分类
- 缺点:训练较难,G和D要均衡好
- 他用一个有监督学习的损失函数来做无监督学习的,他的标号(来自于采样的还是生成的)来自于数据,用了监督学习的损失函数,所以在训练上确实会高效很多,这也是之后自监督学习(比如说BERT)的灵感的来源