
Extracting Motion and Appearance via Inter-Frame Attention for Efficient Video Frame Interpolation
CVPR 2023
Abstract
有效地提取帧间运动和外观信息对视频插帧很重要,之前的工作要么以混合的方式提取这两种信息,要么为每种类型的信息设计单独的模块,这导致效率低下并且表示歧义。本文提出一个新的模块通过统一操作提取帧间运动和外观信息。
Current Methods
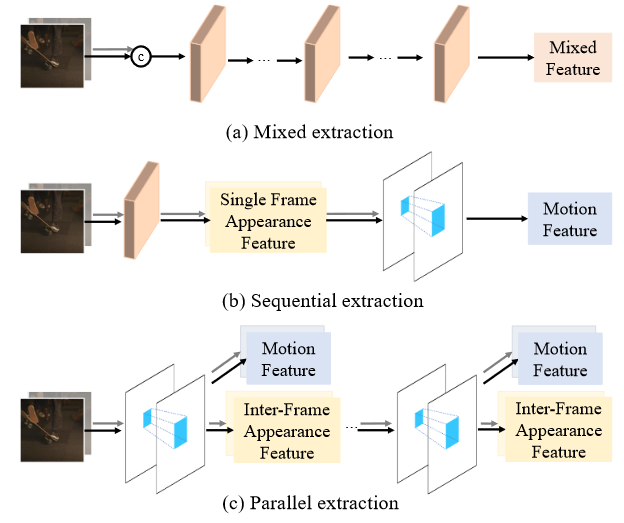
- mixed extraction:将连续的两帧直接按通道拼在一起,经过重复的网络模块提取特征,这个特征既用来建模运动也用来表征外观信息。(a)
-
sequential extraction:采用串行提取两种信息的思路,首先提取每一帧的外观信息,再利用两帧的外观信息提取运动信息,该方法需要针对每种信息单独设计模块导致计算开销大,同时缺乏帧间信息的交互。(b)
- ours:设计一个模块能够同时显式地提取运动信息和帧间交互过的外观信息,并且可以像混合提取范式一样只需要通过控制模块的个数和容量来控制性能。(c)
Model Architecture
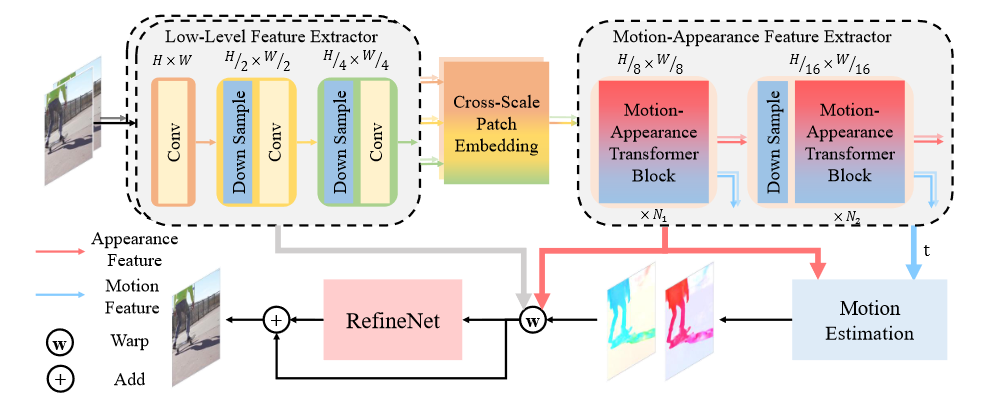
Low-level Feature Extractor
第一步:求第i帧\(I _ {i}\)的low level feature:\(F ( I _ { i } ) = L _ { i } ^ { 0 } , L _ { i } ^ { 1 } , L _ { i } ^ { 2 }\),其中\(F\)是特征提取器,这里\(L\)用的是简单CNN来提取特征,其中\(L _ { i } ^ { k }\)的维度为\(\frac { H } { 2 ^ k } \times \frac { W } { 2 ^ k } \times 2 ^ { k } C\),这样做可以减少计算量但是会造成transformer得不到细节信息,因此需要第二步的操作。
第二步:求第i帧\(I _ {i}\)的cross-scale information:将上述得到的特征图输入到multi-scale dilated convolution中,即\(\frac { H } { 2 ^ k } \times \frac { W } { 2 ^ k } \times 2 ^ { k } C\)的数据对应stride为\(2 ^ {3 - k}\)以及dilation对应为\(2 ^ {2 - k}\)。也就是说不同尺寸对应于不同的反卷积,所以叫做multi-scale dilated convolution。
第三步:fuse:将第二步得到的所有结果先concatenate,然后送入一个 linear layer 得到一个 cross-scale 的 appearance feature,作者称之为\(C_i\)。第二步和第三步归纳在图中为cross-scale patch embedding。
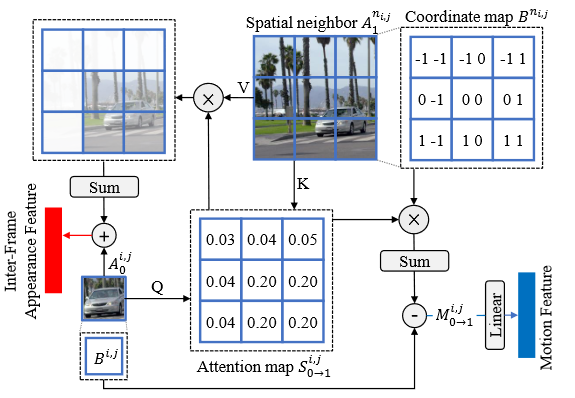
Inter-Frame Attention(IFA)
本项目使用帧间注意力机制来同时提取运动信息和外观信息,动机在于它能够自然地建模帧间运动并同时传递外观信息。
将Low-level Feature Extractor输出的\(C_0\)和\(C_1\)送入到该模块中。
假设已经得到了两帧\(I _ {0}, I _ {1}\)的外观信息分别为\(A _ {0}, A _ { 1 } \in R ^{ \hat { H } \times \hat { W } \times C}\),对于前一帧\(I _ {0}\)的任意区域的特征\(A _ { 0 } ^ { i , j } \in R ^ { C }\),利用后一帧\(I _ {1}\)对应位置的空间相邻位置的特征\(A _ { 1 } ^ { n _ {i , j }} \in R ^ { N \times N \times C }\),其中\(N\)表示相邻位置的window大小,得到query、key/value公式如下: \(\begin{matrix} Q _ {0} ^ {i, j} = A _ { 0 } ^ { i, j } W _ { Q } \\ K _ {1} ^ { n _ {i , j }} = A _ {1} ^ { n _ {i , j } } W _ { K } \\ V _ { 1 } ^ {n _ {i , j }} = A _ { 1 } ^ {n _ {i , j } } W _ { V } \end{matrix}\) 其中\(W _ {Q}, W _ {K},W _ {V} \in R ^{ C \times \hat { C }}\)是线性投影矩阵,然后在\(Q _ {0} ^ {i, j}\)和\(K _ {1} ^ { n _ {i , j }}\)之间做点积并通过softmax操作生成注意力图\(S _ { 0 \rightarrow 1 } ^ { i , j } \in R ^ { N \times N }\),每个位置的值表示\(A _ { 0 } ^ { i , j }\)与其相邻位置的相似程度: \(S _ { 0 \to 1 } ^ { i , j } = S o f t M a x \left( Q _ { 0 } ^ { i , j } ( K _ { 1 } ^ { n _ { i , j } } ) ^ { T } / \sqrt { \hat { C } } \right)\) 利用得到的注意力图可以同时进行外观信息的传递和运动信息的提取。
对于外观信息,首先将\(I _ {1}\)中的相似外观信息进行聚合,然后将其与\(A _ { 0 } ^ { i , j }\)进行融合用于增强前一帧\(I _ {0}\)中的外观信息: \(\widehat { A } _ { 0 } ^ { i , j } = A _ { 0 } ^ { i , j } + S _ { 0 \rightarrow 1 } ^ { i , j } V _ { 1 } ^ { n _ { i , j } }\) 增加了两帧之前的相似区域的 apppearance feature。并且乘的这个 attention值可以为两帧融合出一帧提供信息。
对于运动信息,我们首先创建一个坐标地图\(B \in R ^{ \hat { H } \times \hat { W } \times 2}\),每个位置的值表示在整个图片中的相对位置,(-1,-1)表示左上角,(1,1)表示右下角。通过加权相邻位置的坐标来估计在后一帧\(I _ {1}\)中\(A _ { 0 } ^ { i , j }\)的近似对应位置,通过将\(A _ { 0 } ^ { i , j }\)的初始位置与\(I _ {1}\)中的估计位置相减,得到\(A _ { 0 } ^ { i , j }\)的运动向量\(M _ { 0 \rightarrow 1 } ^ { i , j } \in R ^ { 2 }\)如下: \(M _ { 0 \to 1 } ^ { i , j } = S _ { 0 \to 1 } ^ { i , j } B ^ { n _ { i , j } } - B ^ { i , j }\) 将\(M _ { 0 \rightarrow 1 } ^ { i , j }\)通过线性层即可得到运动特征,在局部直线运动的假设下,可以通过乘以实数\(t\)得到\(I _ {0}\)到\(I _ {t}\)的运动向量:\(M _ { 0 \rightarrow t } ^ { i , j } = t \times M _ { 0 \rightarrow 1 } ^ { i , j }\)。
Transformer Block
将上述帧间注意力模块融入到transformer中并做适当修改如下图所示
提取 bidirectional optical flows F
用的简化的RIFE的方法,直接使用简单的卷积层迭代更新反向映射的光流\(F\)和融合图\(O\),只用了三层CNN。
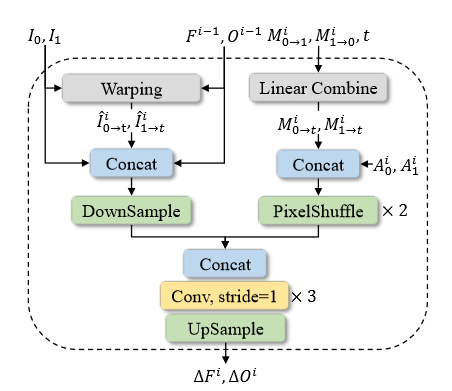
对于上述得到的运动和外观特征,首先对\(M _ { 0 \rightarrow 1 } ^ { i }\)和\(M _ { 1 \rightarrow 0 } ^ { i }\)进行线性缩放得到\(M _ { 0 \rightarrow t } ^ { i }\)和\(M _ { 1 \rightarrow t } ^ { i }\),然后与\(A _ { 0 } ^ { i }\)和\(A _ { 1 } ^ { i }\)进行concatenate。由于两个特征的分辨率较低,因此通过PixelShuffle技术将分辨率提高了四倍。为了迭代更新前一阶段估计的\(F ^ {i-1}\)和\(O ^ {i-1}\),将二者与wraping的原始图像结合进一步提升性能。最后将两个输出concatenate到一起输入到CNN中生成残差。通过双线性插值对残差进行上采样,使其与原始输入的分辨率相同。
RefineNet
用的RIFE的方法,使用了一个简化的U-Net架构
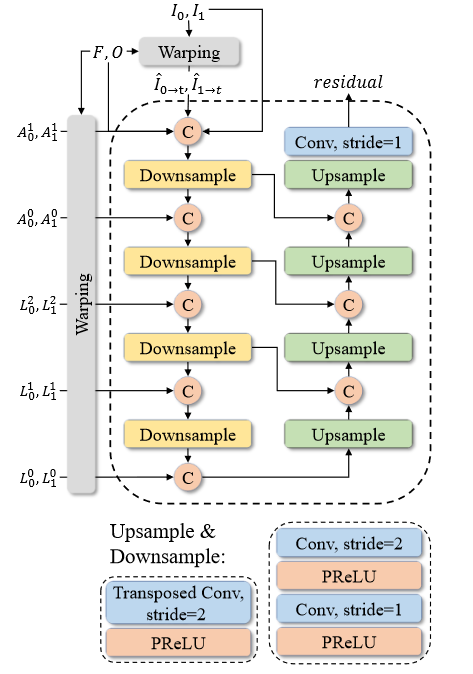
Overall Pipeline
为了降低运算开销,首先利用分层卷积层作为底层特征提取器生成多尺度的外观特征并利用多尺度空洞卷积将信息融合在一起。然后将外观特征输入到transformer特征提取模块中,首先利用获取的运动和外观特征估计双向光流\(F\)和掩码\(O\),并使用他们将输入帧扭曲到t并融合到一起: \(\tilde { I } _ { t } = O \odot B W ( I _ { 0 } , F _ { t \rightarrow 0 } ) + ( 1 - O ) \odot B W ( I _ { 1 } , F _ { t \rightarrow 1 } )\) 其中\(BW\)是向后wrap操作,\(\odot\)表示哈达玛积。最后利用低层特征和帧间外观特征通过RefineNet细化融合后的帧的外观信息。
Loss Function
\[L = L _ { r e c } + \lambda \sum _ { i } C _ { w a r p } ^ { i }\]由两部分组成:wrap loss和reconstruction loss。
wrap loss直接监督通过wraping和fusing输入得到的结果 \(L _ { w a r p } ^ { i } = f ( \tilde { I } _ { t } ^ { i } , I _ { t } ^ { G T } )\) \(L _ { w a r p } ^ { i }\)表示第i次运动估计的wrap loss,\(f\)通常是pixel-wised loss。
reconstruction loss是对最终合成帧的重构质量进行监督 \(L _ { r e c } = f ( \widehat { I } _ { t } , I _ { t } ^ { G T } )\) 应用Laplacian loss作为f,表示了对变形帧与真实值之间的拉普拉斯金字塔进行L1距离测量。