
Creating speech zones with self-distributing acoustic swarms
nature 2023
Abstract
提出第一个演示使用声音进行厘米级分辨率协同导航声学集群(acoustic swarm)。该声学集群形成的自分布无线麦克风阵列和基于注意力的神经网络框架使我们可以在2D空间中分离并定位讲话者。
Content
Self-distributing acoustic swarms
为了设计一个小型化的可以在2D平面上自主导航的声学集群,需要满足以下要求:尽可能地向外扩散,但别掉下去,并且可以从和其他物体的碰撞中恢复正常;机器人直接可以合作并精确定位,以厘米级的精度计算每个机器人的绝对2D位置;低电量时候机器人可以自主导航返回充电。
Robot hardware
基于蓝牙低功耗模块,配备了用于测量距离的陀螺仪和加速器计、用于检测边缘的接近感应光断续器(proximity-sensing photointerruptors)、用于检测剩余电量的机载燃料计等装置。
机器人部署的底座如下图所示

Acoustic swarm localization
使用声学信号实现集群定位。首先发送频率为62.5khz的脉冲,以测量成对机器人之间的距离,然后应用二维定位算法基于距离估计机器人的坐标。
测量相对距离:机器人广播脉冲,其他机器人计算接收到脉冲的时间差,则距离为光速与时间差的乘积。设计了一个双麦克风算法来精确计算接收到脉冲的时间。
计算绝对2D坐标:通过pairwise 2D localization pipeline。一个机器人停留在底座上,并经过轨道上的所有黑色检查点,沿途发出脉冲信号,其余机器人根据信号计算其与每个检查点的距离。一旦机器人到达最后一个检查点,外部机器人发送脉冲信号用于更精确测量距离。
Swarm dispersal
留下一个机器人在底座,其他机器人尽可能远的分散在2D平面上。在扩散之前首先对机器人在底座上进行排序,并让每个机器人定位到相应的检查点上。让每个机器人以等分的角度扩散,直到到达平面边缘或碰到障碍物才停止扩散。
Navigating back to the base(*)
假设一个clear zone在底座的周围,其中没有任何物体。这个区域可以用于机器人的操作和与底座的对接。假设机器人扩散的路径上没有任何后续放置的物体,因此机器人可以原路返回,同时底座内的机器人发出脉冲信号,当外部机器人到达clear zone的边缘时就停止。一旦所有机器人到达clear zone后,执行上述2D定位算法进行定位。在每个机器人返回的过程中,其他机器人充当landmark。
Speech separation and 2D localization
定位房间中所有讲话者的位置并进行声音分离。
2D localization via separation
根据到达时间差(TDoA)对每个位置进行时间偏移,以使麦克风通道与可能存在说话者的位置对齐。为此,我们将根据候选位置到每对麦克风之间的信道传播时间差来调整麦克风信号。如果该位置包含说话者,则调整后的扬声器信号将在所有信道上对齐,而来自其他位置的信号则不会对齐。因此,通过检查输出信号振幅,我们可以检查每个位置是否存在说话者,从而计算出说话者的数量并获得它们的二维位置。
但是我们需要在3D空间中进行搜索,因为讲话者和麦克风之间的高度差异为多通道信号引入了额外的时间延迟。为了解决3D搜索,结合了神经语音分离和传统声源定位方法。
首先通过Steered-Response Power Phase Transform (SRP-PHAT) 算法对搜索空间进行剪枝,SRP-PHAT是一种信号处理技术,可以通过分析所有 microphone-pairs 之间的相位差来实现粗略的声音源定位。SRP-PHAT输出与每个可能候选点对齐的信号功率。我们通过丢弃低输出功率的区域来修剪搜索空间。
然后使用一个基于注意力的分离模型在剩余空间中寻找说话者的位置。结合了UNet的encoder-decoder与一个自注意力的transformer encoder层。
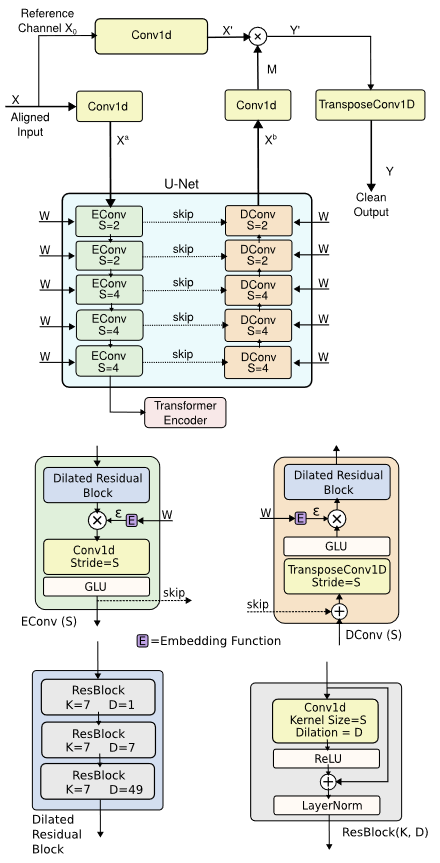
Separation via 2D localization
在现实世界的混响环境中,由于讲话者之间的cross-talk成分,面向定位的分离网络的输出信噪比可能很低。同时这种方法并未充分利用我们从2D定位网络中获取的其他讲话者的定位信息。因此利用inter-speaker attention。
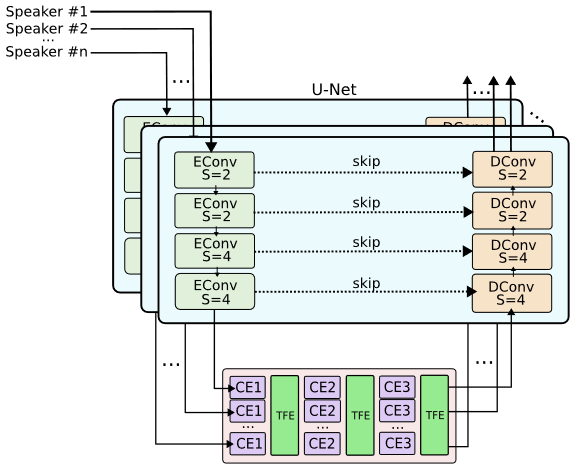
对于每个说话者,我们将M个麦克风信号对其到其2D位置,将结果的SxM信号输入到下图中的分离模型中。此模型为每个说话者分别应用encoder和decoder以对齐麦克风数据。bottleneck block通过interspeaker attention解决cross-talk问题,首先对每个讲话者在时间维度上使用一个conformer network,独立处理每个讲话者。然后使用transformer encoder在说话者维度上应用注意力,使模型能够在不同说话者channel上关联信息。交替应用讲话者内部和讲话者之间的注意力层。
Contribution
- 麦克风阵列可以自主地在一个2D表面上扩散,并自主地回去充电
- 设计了一个联合2D定位和语音分离框架
- 泛化性很好
Idea
这个论文感觉还有很多地方没读懂,没有针对模型架构或者实现方法想到什么idea
- Navigating back to the base的过程中有物体在返回路径上阻挡
- clear zone中也有物体
- 这个最终实现的目标我有点没看懂,分离mute zone和active zone然后每个zone里面的人只能听到这个区域的声音吗,还是这两个区域之外的人可以选择听到哪些声音。
- 要是让指定区域内的人只能听到该区域内部的声音,能不能和semhear那个论文结合一下,通过可穿戴设备将过滤后的该区域内的所有讲话者声音都保留或者可以把其他杂音过滤掉之类的
- 能不能扩展到将麦克风部署到整个3D空间而不是一个2D空间
- 扩散和返回充电感觉有点麻烦,是不是每次充电之后都要重新执行算法进行扩散,能不能每次记住前一次的位置或者路径然后快速部署,以及记住返回充电的路径之类的
- 如果在平面上遇到物体就停止,那么如果在给定角度上离底座很近就有物体效果可能会差一点,能不能考虑避开障碍物
- 可不可以手动部署在3D空间中的不同2D平面上,或者将算法扩展到三维空间中