
Conformer: Convolution-augmented Transformer for Speech Recognition
INTERSPEECH 2020
Abstract
Transformer擅长捕捉基于内容的全局交互但不擅长捕捉局部特征,而CNN擅长利用局部特征,然而需要更多更深的层去捕捉全局信息。因此本文提出CNN增强的transformer模型Conformer,将CNN融入到transformer中,得到的很好的实验效果。
Architecture
每个Conformer模块主要包括三部分,两个Feed Forward Module,一个Multi-Head Self-Attention Module,一个Convolution Module。每一步骤都采用残差连接,下面分别介绍这三个模块。
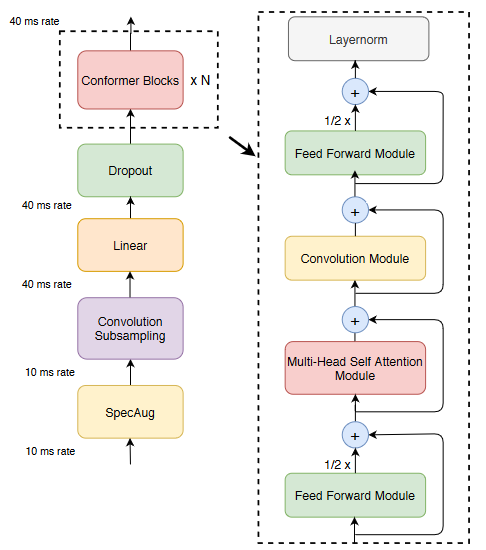
Multi-Headed Self-Attention Module
使用相对位置编码:更适用于处理可变长度输入的场景

Convolution Module

Feed Forward Module
在transformer的基础上稍作改动,用sigmoid激活函数代替relu激活函数,修改了layernorm的位置等。
