
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
ACL 2019
Abstract
与ELMo以及GPT不同的是BERT用于预训练双向的表示,ELMo使用的是双向的RNN,GPT使用的是单向的Transformer。因此只需要加一个额外的输出层就可以在很多nlp任务上达到sota。随后介绍了一下BERT在11个数据集上的sota效果,与现有sota对比。
先写与别人比有什么改进,然后写效果对比好在哪里。
Architecture
主要模型架构是一个多层双向的标准Transformer encoder模块。
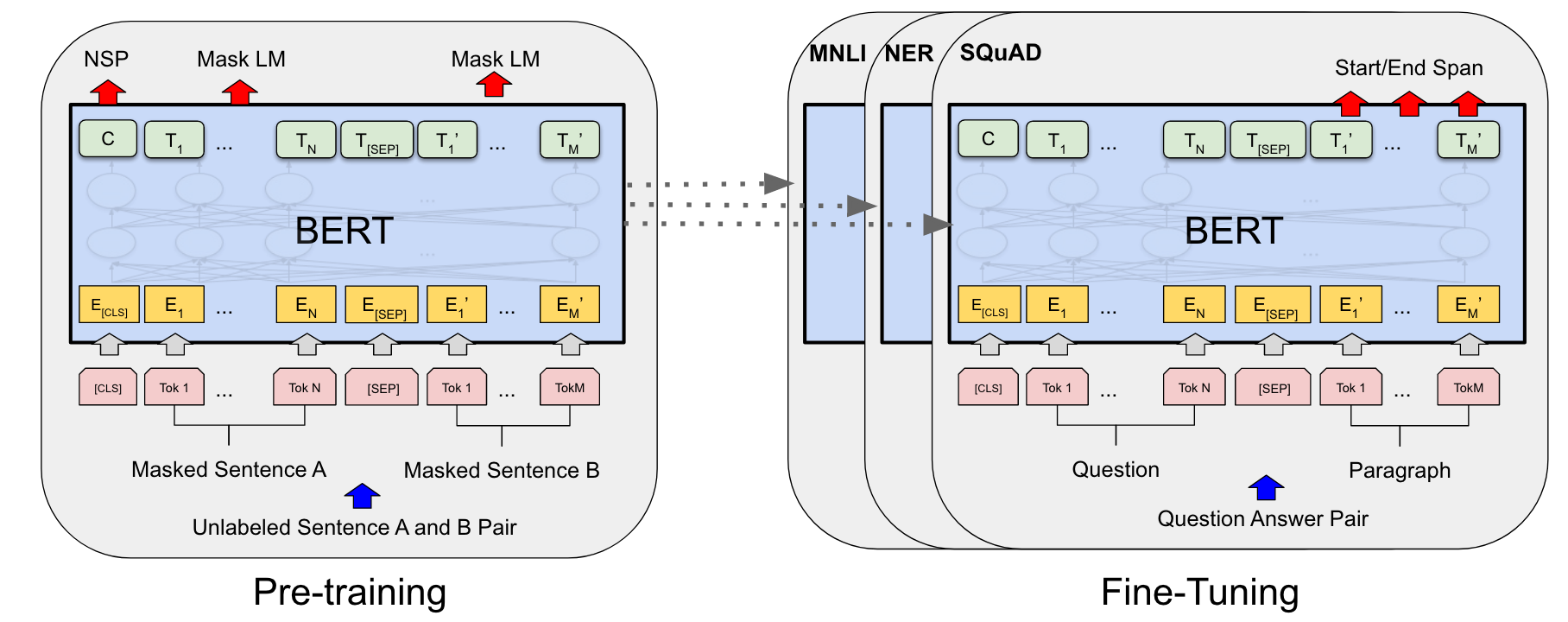
- pre- training:在没有标号的数据,通过MLM任务进行训练。首先找一对句子,然后对两个句子的部分词进行mask,随后在句子前加入特殊token CLS,在句子中间加入特殊token SEP。将这些token都输入到模型中,BERT会为每个token输出一个向量,随后可以用输出的向量做NSP和Mask LM任务。随后就可以用预训练好的BERT进行微调做下游任务。
- fine- tuning:权重初始化为预训练得到的权重,然后用有标号数据进行微调。每个下游任务都微调出一个模型。
Experiment
呈现了BERT在11个下游任务中的具体结果,详细说了在GLUE、SQuAD v1.1、SQuAD v2.0、SWAG上的结果。
Others
- 每个输入序列的第一个token是一个特殊的分类字符CLS,该token最后隐藏层的输出被用作分类任务中的序列表示。
- embedding:在BERT中对于token的embedding是将token embedding,segment embedding,position embedding加和得到,每个token都包含了词信息,位置信息和段落信息。
- 训练使用的是MLM预训练任务,随即掩盖输入中的部分词,目的是根据上下文来预测被盖住的这些词的什么。
- NSP:使用CLS的输出向量输入到后面的全连接层做二分类任务,预测输入的A和B两句话是不是一对。
- Mask LM:使用mask token的输出通过全连接层和softmax做多分类任务,预测被mask的内容是什么。